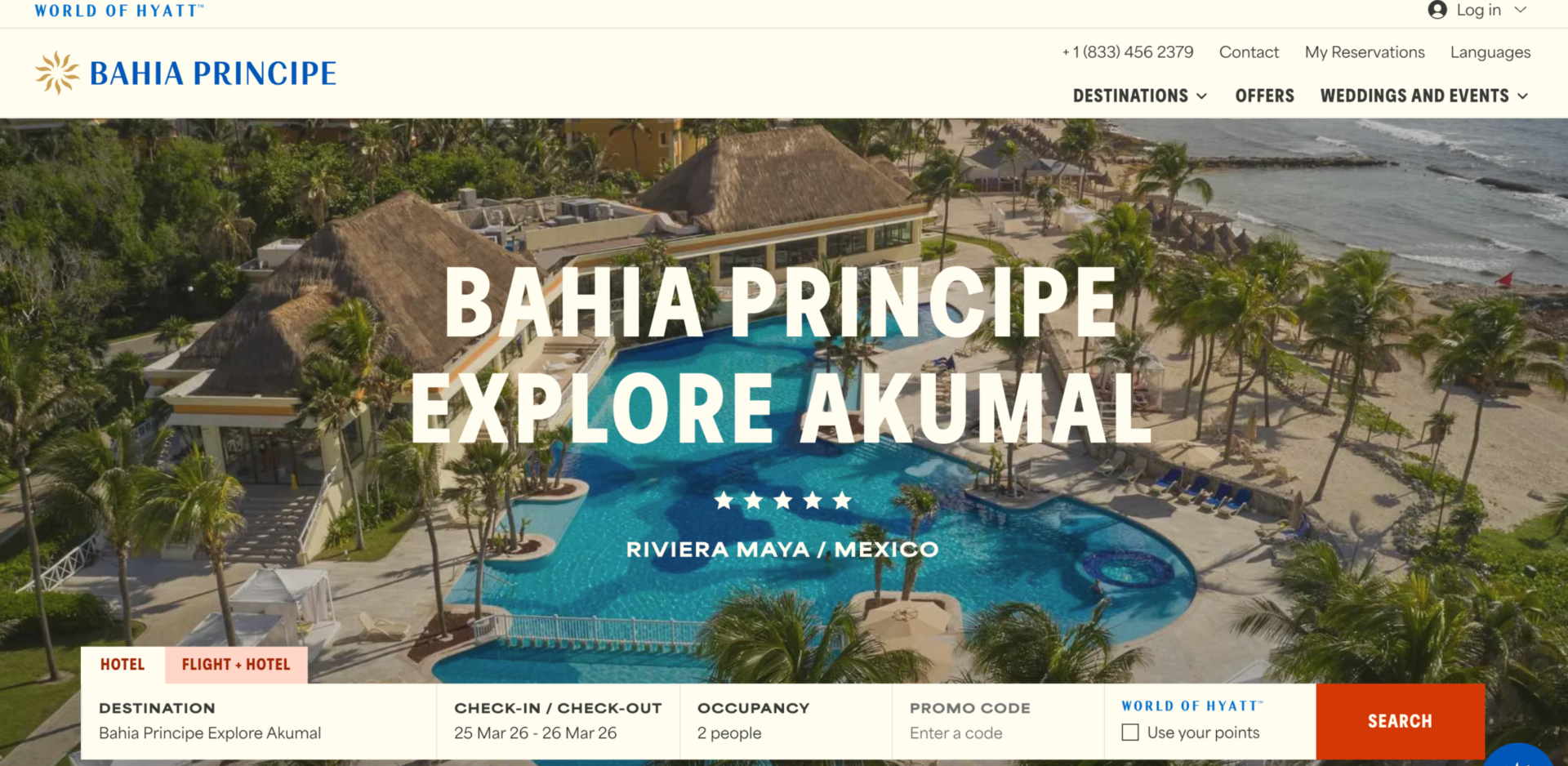
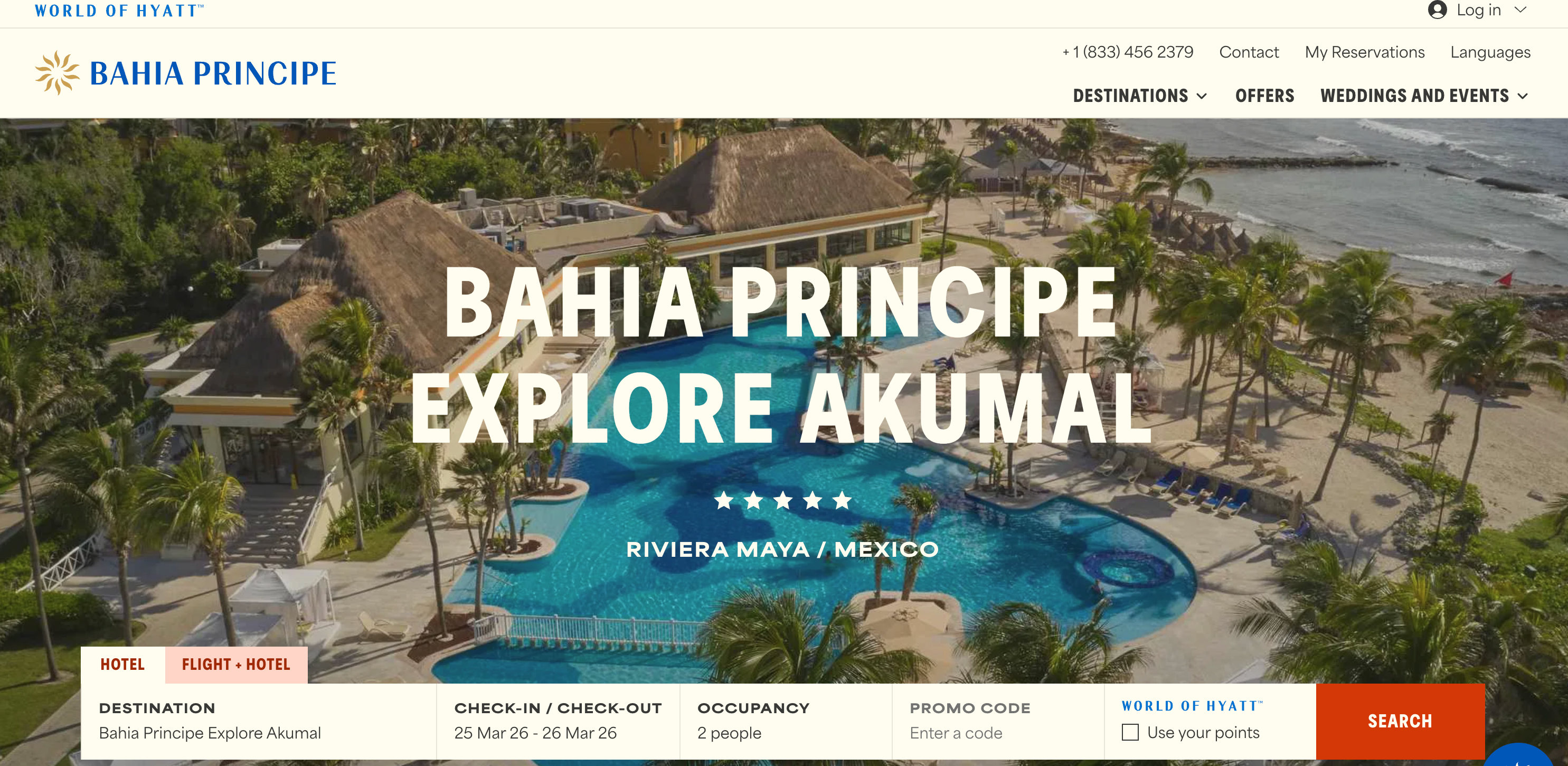
All-inclusive resort brand Bahia Principe has officially joined the World of Hyatt family. This means you can now earn and redeem World of Hyatt points by staying at one of the Bahia Principe hotels in the Dominican Republic, Mexico, Jamaica or Spain.
You can book through the World of Hyatt website or through your chosen Bahia Principe resort’s website. On the main page, you’ll see the option to use your World of Hyatt points when searching for availability.
BAHIA PRINCIPE
Unlike Mr and Mrs Smith properties, which now use dynamic pricing since being acquired by Hyatt, Bahia Principe resorts will follow Hyatt’s fixed award chart. World of Hyatt members can earn 5 base points per eligible $1 spent on room rates and 4 bonus points per eligible $1 spent for World of Hyatt Credit Card (see rates and fees) members, among other perks.
The cherry on top: Hyatt is running a promotional offer to celebrate this new partnership. Members can earn double points on qualifying stays at participating Bahia Principe properties through June 30. Just register here by May 30, and stay between April 1 and June 30.
Some of the best Bahia Principe hotels to book with Hyatt points
While many Bahia Principe properties are similar in their all-inclusive offerings, they differ in landscape and clientele. Some are more upscale adults-only options, while others are family-focused and offer access to kid-friendly activities. Here are some of the best options to use as inspiration for your next stay.
Bahia Principe Luxury Akumal
This beachside Mexican resort sits between popular hotspots Playa Del Carmen and Tulum. It offers three pools, a spa and plenty of dining venues and bars. Accommodations range from swim-up suites with private terraces to multibedroom suites that can fit the whole family. Rates start at around $300 or 20,000 World of Hyatt points per night.
Bahia Principe Escape Samana
This adults-only property in the Dominican Republic offers direct beach access and plenty of opportunities to unplug and enjoy nature. There’s a spa, a pool and multiple dining venues to choose from, and the secluded vibe is great for a relaxing, romantic getaway. You can select a basic room or a sea-view suite.
Rates start at about $150 or 23,000 World of Hyatt points per night.
Bahia Principe Escape Runaway Bay
There are three pools, five restaurants, three bars and plenty of event and meeting spaces at this Jamaican resort, and travelers can choose from suites that offer living areas, terraces, balconies and even sweeping ocean views. And although this is an adults-only hotel, it’s part of a larger Bahia Principe complex that houses a family-friendly option, Bahia Principe Grand Jamaica.
Reward your inbox with the TPG Daily newsletter
Join over 700,000 readers for breaking news, in-depth guides and exclusive deals from TPG’s experts
Rates start at $320 or 21,000 World of Hyatt points per night.
Bahia Principe Luxury Sian Ka’an
If you’re more of a jungle person than a beach person, Bahia Principe Luxury Sian Ka’an might be up your alley. Surrounded by lush vegetation in Mexico’s Riviera Maya, this adults-only resort includes four restaurants, four pools and a spa. Plus, it sits beside an 18-hole golf course.
Rates start at around $220 or 20,000 World of Hyatt points per night.
If you’d like to plan a trip to one of these Bahia Principe properties — or a different Hyatt hotel — consider applying for the World of Hyatt Business Credit Card (see rates and fees). You can earn 80,000 bonus points after you spend $10,000 on purchases in your first three months from account opening.
Data science is the study of how to gain insightful knowledge from data for business choices, developing strategies, and other reasons utilizing state-of-the-art analytical technologies and scientific ideas. Businesses are becoming aware of its significance: among other things, data science insights assist companies in improving their marketing and sales efforts as well as operational effectiveness. They might eventually give you a competitive edge over other businesses.
Data Science combines a number of fields, including statistics, mathematics, software programming, predictive analytics, data preparation, data engineering, data mining, machine learning, and data visualization. Skilled data scientists are generally responsible for it, however, entry-level data analysts may also be engaged. Additionally, a growing number of firms now depend in part on citizen data scientists, a category that can encompass data engineers, business intelligence (BI) specialists, data-savvy business users, business analysts, and other employees without a formal experience in Data Science.
Become a Data ScienceCertified professional by learning this HKRData Science Training!
What is Linear Algebra
Within Data Science and ML, linear algebra is a field of mathematics that is very helpful. In machine learning, linear algebra is perhaps the most crucial math concept. The vast majority of machine learning models may be written as matrices. A matrix is a common way to represent a dataset. The preprocessing, transformation, and assessment of data and models require linear algebra.
A study of linear algebra may involve the following:
Vectors
Matrices
Transpose of a matrix
The inverse of a matrix
Determinant of a matrix
Trace of a matrix
Dot product
Eigenvalues
Eigenvectors
Why learn Linear Algebra in Data Science?
One of the fundamental building elements of Data Science is linear algebra. Without a solid foundation, you cannot erect a skyscraper, can you? Try to picture this example:
You wish to use Principal Component Analysis to minimize the dimensionality of your data (PCA). If you were unsure of how it would impact your data, how would you choose how many Principal Components to keep? Obviously, in order to make this choice, you must be familiar with the workings of the algorithm.
You will be able to gain a better sense for ML and deep learning algorithms and stop treating them as mysterious black boxes if you have a working knowledge of linear algebra. This would enable you to select suitable hyperparameters and create a more accurate model. Additionally, you would be able to develop original algorithms and algorithmic modifications.
Linear Algebra Applications for Data Scientists
We will now learn more about the most common application of linear algebra for data scientists:
Machine learning: loss functions and recommender systems
Without a question, the most well-known use of artificial intelligence is machine learning (AI). Systems automatically learn and get better with experience employing machine learning algorithms, free from human intervention. In order to detect trends and learn from them, machine learning works by creating programs that access and analyze data (whether static or dynamic). The algorithm can use this expertise to analyze fresh data sets once it has identified relationships in the data. (See this page for more information on how algorithms learn.)
Machine learning uses linear algebra in many different ways, including loss functions, regularization, support vector classification, and plenty more.
Machine learning algorithms function by gathering data, interpreting it, and then creating a model via various techniques. They can then forecast upcoming data queries depending on the outcomes.
Now, we may assess the model’s correctness by utilizing linear algebra, specifically loss functions. In a nutshell, loss functions provide a way to assess the precision of the prediction models. The output of the loss function will be greater if the model is completely incorrect. In contrast, a good model will cause the function to return a lower value.
Modeling a link involving a dependent variable, Y, and numerous independent variables, Xi’s, is known as regression. We attempt to build a line in place on these variables upon plotting these points, and we utilize this line to forecast future values of Xi’s.
The two most often used loss functions are mean squared error and mean absolute error. There are many different forms of loss functions, many of which are more complex than others.
A subset of machine learning known as recommender systems provides consumers with pertinent suggestions based on previously gathered data. In order to forecast what the present user (or a new user) might like, recommender systems employ data from the user’s prior interactions with the algorithm focused on their interests, demographics, and other available data. By tailoring material to each user’s tastes, businesses can attract and keep customers.
The performance of recommender systems depends on two types of data being gathered:
Characteristic data: Knowledge of things, including location, user preferences, and details like their category or price.
User-item interactions: Ratings and the volume of transactions (or purchases of related items).
Artificial intelligence’s Natural Language Processing (NLP) field focuses on how to connect with people through natural language, most frequently English. Applications for NLP encompass textual analysis, speech recognition, and chatbot.
Applications such as Grammarly, Siri, and Alexa are all based on the concept of NLP.
Word embedding
Text data cannot be understood by computers, not by its own. We use NLP algorithms on text since we need to mathematically express the test data. The use of algebra is now necessary. A sort of word representation known as word embedding enables ML algorithms to comprehend terms with comparable meanings.
With the backdrop of the words still intact, word embeddings portray words as vectors of numbers. These representations are created using the language modeling learning technique of training various neural networks on a huge corpus of text. Word2vec is among the more widely used word embedding methods.
Computer vision: image convolution
Using photos, videos, and deep learning models, the artificial intelligence discipline of computer vision teaches computers to comprehend and interpret the visual environment. This enables algorithms to correctly recognize and categorize items.
In applications like image recognition as well as certain image processing methods like image convolution and image representation like tensors, we utilize linear algebra in computer vision.
Image Convolution
Convolution results from element-wise multiplying two matrices and then adding them together. Consider the image as a large matrix and the kernel (i.e., convolutional matrix) as just a tiny matrix used for edge recognition, blurring, as well as related image processing tasks. This is one approach to conceiving image convolution. As a result, this kernel slides over the image from top to bottom and from left to right. While doing so, it performs arithmetic operations at every image’s (x, y) location to create a distorted image.
Different forms of image convolutions are performed by various kernels. Square matrices are always used as kernels. They are frequently 3×3, however, you can change the form depending on the size of the image.
Acquire Data Science with R certification by enrolling in the HKR Data Science with R Training program in Hyderabad!
Subscribe to our YouTube channel to get new updates..!
Where do we use linear algebra in Data Science?
Data Scientists often make use of Linear Algebra for various applications including:
Vectorized Code: To create vectorized codes that are relatively more effective than their non-vectorized counterparts, linear algebra is helpful. This is so that results from vectorized codes can be produced in a single step instead of results from non-vectorized codes, which frequently involve numerous steps and loops.
Dimensionality Reduction: In the preparation of data sets required for machine learning, dimensionality reduction is a crucial step. This is particularly true for big data sets or those with many attributes or dimensions. Many of these characteristics may occasionally have a strong correlation with one another.
The speed and effectiveness of the ML algorithm are improved by doing dimensionality reduction on a big data set. This is due to the fact that the algorithm only needs to consider a small number of features before producing a forecast.
Linear Algebra for Data Preprocessing – Linear algebra is used for data preprocessing in the following way:
Import the required libraries for linear algebra such as NumPy, pandas, pylab, seaborn, etc.
Read datasets and display features
Define column matrices to perform data visualization
Covariance Matrix– One of the most crucial matrices in Data Science and ML is the covariance matrix. It offers details on the co-movement (correlation) of characteristics. We can create a scatter pair plot to see how the features are correlated. One could construct the covariance matrix to determine the level of multicollinearity or correlation between characteristics. The covariance matrix could be written as a symmetric and real 4 x 4 matrix. A unitary transformation, commonly known as a Principal Component Analysis (PCA) transformation, can be used to diagonalize this matrix. We note that the sum of the diagonal matrix’s eigenvalues equals the total variance stored in features because the trace of a matrix stays constant during a unitary transformation.
Linear Discriminant Analysis Matrix – The Linear Discriminant Analysis (LDA) matrix is another illustration of a realistic and symmetrical matrix in Data Science. This matrix could be written as follows
where SW stands for the scatter matrix within the feature and SB for the scatter matrix between the feature. It implies that L is real and symmetric because the matrices SW & SB are also realistic and symmetrical. A feature subspace with improved class separability and decreased dimensionality is created by diagonalizing L. So, whereas PCA is not a supervised method, LDA is.
Data Science Certification Training
Weekday / Weekend Batches
Conclusion
Often a skipped-over concept due to premeditated assumptions of difficulty, a good hold over linear algebra could help build a crucial foundation for those aspiring to have flourishing careers in Data Science.
To provide the best experiences, we use technologies like cookies to store and/or access device information. Consenting to these technologies will allow us to process data such as browsing behavior or unique IDs on this site. Not consenting or withdrawing consent, may adversely affect certain features and functions.
Functional
Always active
The technical storage or access is strictly necessary for the legitimate purpose of enabling the use of a specific service explicitly requested by the subscriber or user, or for the sole purpose of carrying out the transmission of a communication over an electronic communications network.
Preferences
The technical storage or access is necessary for the legitimate purpose of storing preferences that are not requested by the subscriber or user.
Statistics
The technical storage or access that is used exclusively for statistical purposes.The technical storage or access that is used exclusively for anonymous statistical purposes. Without a subpoena, voluntary compliance on the part of your Internet Service Provider, or additional records from a third party, information stored or retrieved for this purpose alone cannot usually be used to identify you.
Marketing
The technical storage or access is required to create user profiles to send advertising, or to track the user on a website or across several websites for similar marketing purposes.