Back at CES, Samsung showed off a new line of speakers and two of its 2026 soundbars. Today, the company announced pricing for the entire suite of new products, including two soundbars that weren’t inside its showroom in Vegas. All but two of the new devices are available to order now, so you might not have to wait to get your hands on some new Samsung audio gear.
Let’s start with the Music Studio 7 and Music Studio 5 speakers. The Music Studio 7 is the more rectangular model in the duo. It’s a 3.1.1-channel unit with left, right and center speakers alongside one woofer and one up-firing driver. This $500 device is also equipped with Pattern Control tech to direct the sound evenly through the room while keeping distortion to a minimum. The more circular Music Studio 5 has a 2.1-channel configuration composed of two tweeters and a single woofer. It has waveguide technology to evenly disperse the sound and costs $300.
Both the Music Studio 7 and Music Studio 5 use AI processing to customize the sound based on the room and the content. Those capabilities come in the form of Samsung’s Dynamic Bass Control and SpaceFit Sound Pro room calibration features. Both speakers also use Active Voice Amplifier Pro to boost dialogue.
Two Music Studio 7 speakers being used with a TV (Samsung)
Yes, this means you can use a pair of either model as your living room setup. In fact, they can work with a compatible TV or soundbar to employ Samsung’s Q-Symphony feature that uses all of your speakers as an immersive group. Samsung is also expanding Q-Symphony to work with up to five of its audio devices and the feature will automatically adjust the sound based on speaker locations. Those upgrades seem an awful lot like LG’s Sound Suite and Dolby Atmos FlexConnect, if you ask me.
Samsung revealed its flagship soundbar, the Q990H, at CES. Unfortunately, the company is keeping the same overall design it’s been using for about years now, so I think it’s time for a change. This is the company’s 11.1.4-channel Dolby Atmos option that comes with rear satellite speakers and a subwoofer for $2,000. Samsung’s home theater features like Dynamic Bass Control, SpaceFit Sound Pro and Adaptive Sound are all here, but there are also two new features on the Q990H for 2026.
First, Samsung promises that Sound Elevation will improve the audio by making dialogue sound like its coming from where characters are on the screen rather than the position of your soundbar. There’s also Auto Volume, which will supposedly nix sudden volume jumps as you switch channels or streaming services.
The QS90H is the member of Samsung’s 2026 soundbar lineup that really impressed me at CES. The company says this is its first “all-in-one” soundbar, which means you shouldn’t have to use a subwoofer for adequate bass. Other companies have made that claim, and it’s almost never true, but the $1,000 QS90H pumped out some great low-end tone back in Vegas. That’s thanks to four built-in woofers and an overall 7.1.2-channel setup.
The QS90H has a similar design to the existing QS700 soundbar (Samsung)
Like the QS700F, the QS90H has a gyro sensor that automatically detects if it’s sitting flat on a shelf or mounted on a wall. This allows the soundbar to automatically adjust the sound based on its position so you don’t sacrifice performance for what looks best in your home. The QS90H also offers Q-Symphony, SpaceFit Sound Pro room calibration, Adaptive Sound, Active Voice Amplifier Pro and Dynamic Bass Control — plus the new Sound Elevation and Auto Volume from the Q990H.
Two other soundbars that Samsung didn’t discuss at CES are the Q930H ($1,500) and the Q800H ($1,100). As you might expect based on the numbers, these two models sit below the Q990H in the company’s lineup. The Q930H is a 9.1.4-channel option that comes with rear speakers and a subwoofer in the box. In terms of features, Q-Symphony, SpaceFit Sound Pro room calibration, Adaptive Sound, Voice Amplifier Pro and Sound Elevation are all here. Step down to the Q800H and you’ll get all of those features in a 5.1.2-channel arrangement. This soundbar only comes with a subwoofer though. It’s also worth noting that both the Q930H and Q800H have a similar angular design to the Q900H.
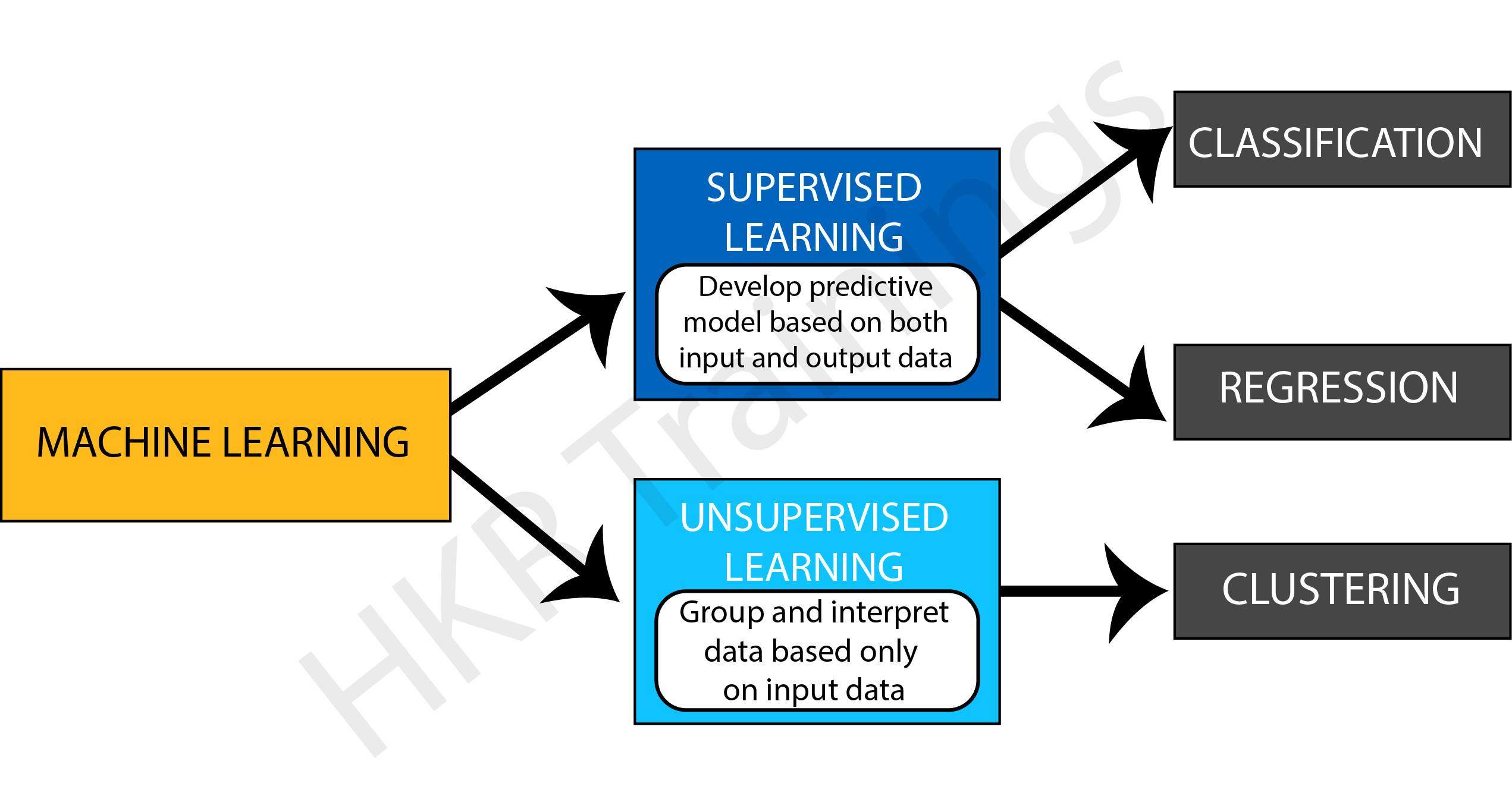
The Classification algorithm is a supervised learning method that trains data to determine the category of future observations. This is why firstly, let us understand what is supervised learning.
What is Supervised Learning
Supervised learning develops a function to predict a defined label based on the input data.
The model in Supervised Learning learns by action. During training, the model examines which label is related to the given data and, as a result, can identify patterns between the data and particular labels.
Let us understand supervised learning with an example of Speech Recognition. It is an application where you train an algorithm with your voice. Virtual assistants such as Google Assistant and Siri, which recognize and respond to your voice, are the most well-known real-world supervised learning applications.
Supervised Learning might sort data into categories (a classification challenge) or predict a result (regression algorithms). This article will specifically address everything we need to know about classification in Machine Learning.
What is Classification in Machine Learning?
The process of recognizing, interpreting, and classifying objects or thoughts into various groups is known as classification. Machine learning models use a variety of algorithms to classify future datasets into appropriate and relevant categories with the help of already-categorized training datasets.
In other words, classification is a type of “pattern recognition.” In this case, classification algorithms applied to training data detect the same pattern (same number sequences, words, etc.) in consecutive data sets.
There are four primary classification tasks you could come across:
Binary Classification
Multi-Class Classification
Multi-Label Classification
Imbalanced Classification
Binary Classification
The term “binary classification” refers to tasks that can provide one of two class labels as an output. In general, one is regarded as the normal state, while the other is abnormal. The following examples can assist you in better comprehending them.
For example, for email spam detection, the normal condition is “not spam,” whereas the abnormal state is “spam.” “Likewise, Cancer not found” is the normal condition of an activity involving a medical test, whereas “cancer identified” is the abnormal state.
The normal state class is usually allocated the class label 0, whereas the abnormal state class is assigned the class label 1.
Some of the popular algorithms used for binary classification are:
Decision Trees
Logistic Regression
Support Vector Machine
k-Nearest Neighbors
Naive Bayes
Machine Learning Training
Master Your Craft
Lifetime LMS & Faculty Access
24/7 online expert support
Real-world & Project Based Learning
Multi-Label Classification
We refer to multi-label classification tasks as those in which we need to assign two or more distinct class labels that can be predicted for each case. A simple example is photo classification, in which a single shot may contain many items, such as a puppy or an apple, and so on. In this type of classification, you can predict many labels rather than just one.
The most common algorithms are:
Multi-label Random Forests
Multi-label Decision trees
Multi-label Gradient Boosting
Multi-Class Classification
Tasks that have two or more class labels are called multi-class classification.
The multi-class classification does not differentiate between normal and abnormal results.
In some situations, the number of class labels might be rather big. For instance, a model may predict that a photograph belongs to one of thousands or tens of thousands of faces in a facial recognition system. Examples are classified into one of several known classes.
Some of the popular algorithms used for multi-class classification are:
Naive Bayes
k-Nearest Neighbors
Random Forest
Gradient Boosting
Decision Trees
Imbalanced Classification
Imbalanced Classification refers to tasks in which the number of items in each class is distributed unequally. In general, unbalanced classification problems are binary classification tasks in which most of the training dataset belongs to the normal class and just a small percentage to the abnormal class.
Learners in Classification Problem
There are two types of learners in a classification problem, namely:
Eager Learners
Lazy Learners
Eager Learners
Eager learning occurs when a machine learning algorithm constructs a model shortly after obtaining training data. It’s named eager because the first thing it does when it obtains the data set is, it creates the model. The training data is then forgotten. When new input data arrives, the model is used to evaluate it. The vast majority of machine learning algorithms are eager to learn.
Lazy Learners
Lazy learning, on the other hand, occurs when a machine learning algorithm does not develop a model immediately after receiving training data but instead waits until it is given input data to analyze. It’s named lazy because it waits until it’s absolutely essential to construct a model if it builds any at all. It only saves training data when it receives it. When the input data arrives, it uses the previously stored data to evaluate the output. Instead of learning a discriminative function from the training data, the lazy learning algorithm “memorizes” the training dataset. The eager learning algorithm, on the other hand, learns its model weights (parameters) during training.
Types of Machine learning Classification Algorithms
Classification algorithms use input training data in machine learning to predict the likelihood or probability that the following data will fall into one specified category. One of the most popular classifications used to sort emails into “spam” and “non-spam” categories, as employed by today’s leading email service providers.
They are two types of classification models, namely:
Linear Models
Non-linear Models
1. Linear Models
Support Vector Machine
The support vector machine (SVM) is a frequently used machine learning technique for classification and regression problems. It is, however, mostly employed to tackle categorization difficulties. SVM’s main goal is to determine the best decision boundaries in an N-dimensional space that can classify data points, and the optimal decision boundary is known as the Hyperplane. The extreme vector is chosen by SVM to locate the hyperplane, and these vectors are referred to as support vectors.
Logistic Regression
In logistic regression, the sigmoid function returns the probability of a label. It is used widely when the classification problem is binary, for example, true or false, win or lose, positive or negative.
Logistic regression is used to determine the right fit between a dependent variable and a set of independent variables. Because it quantifies the factors that lead to categorization, it beats alternative binary classification algorithms like KNN.
Subscribe to our YouTube channel to get new updates..!
2. Non-Linear Models
Decision Tree
The classification model is developed using the decision tree algorithm as a tree structure. The data is then divided down into smaller structures and connected to an incremental decision tree to complete the process. The final output looks like a tree, complete with nodes and leaves. Using the training data, the rules are learned one by one, one by one. Every time a rule is learned, the tuples that cover the rules are removed. The technique is repeated on the training set until the termination point is reached.
The tree is built using a recursive top-down divide and conquer method. A leaf symbolizes a classification or decision, and a decision node will contain two or more branches. The root node of a decision tree is the highest node that corresponds to the best predictor, and the best thing about a decision tree is that it can handle both category and numerical data.
Kernel SVM
A kernel in SVM is a function that assists in problem resolution. They provide you shortcuts so you don’t have to complete hard calculations. Kernel is remarkable since it allows us to go to higher dimensions and do smooth calculations. It is possible to work with an infinite number of dimensions with kernels.
K-Nearest Neighbor
The K-Nearest Neighbor technique divides data into groups based on the distance between data points and is used for classification and prediction. The K-Nearest Neighbor algorithm implies that data points near together must be similar. Hence, the data point to be classed will be grouped with the closest cluster.
Naive Bayes
The classification algorithm Naive Bayes is based on the assumption that predictors in a dataset are independent. This implies that the features are independent of one another. For example, when given a banana, the classifier will notice that the fruit is yellow in color, rectangular in shape, and long and tapered. These characteristics will add to the likelihood of it becoming a banana in its own right and are not reliant on one another. Naive Bayes is based on the Bayes theorem, which is represented as:
P(A|B) = (P(A) P(B|A)) / P(B)
Here: P(A | B) = how likely B happens P(A) = how likely A happens P(B) = how likely B happens P(B | A) = how likely B happens given that A happen
Stochastic Gradient Descent
It is an extremely effective and simple method for fitting linear models. If the sample data is vast, Stochastic Gradient Descent is beneficial. For classification, it provides a variety of loss functions and penalties.
The only benefit is the ease of implementation and efficiency. Still, stochastic gradient descent has several drawbacks, including the need for many hyper-parameters and sensitivity to feature scaling.
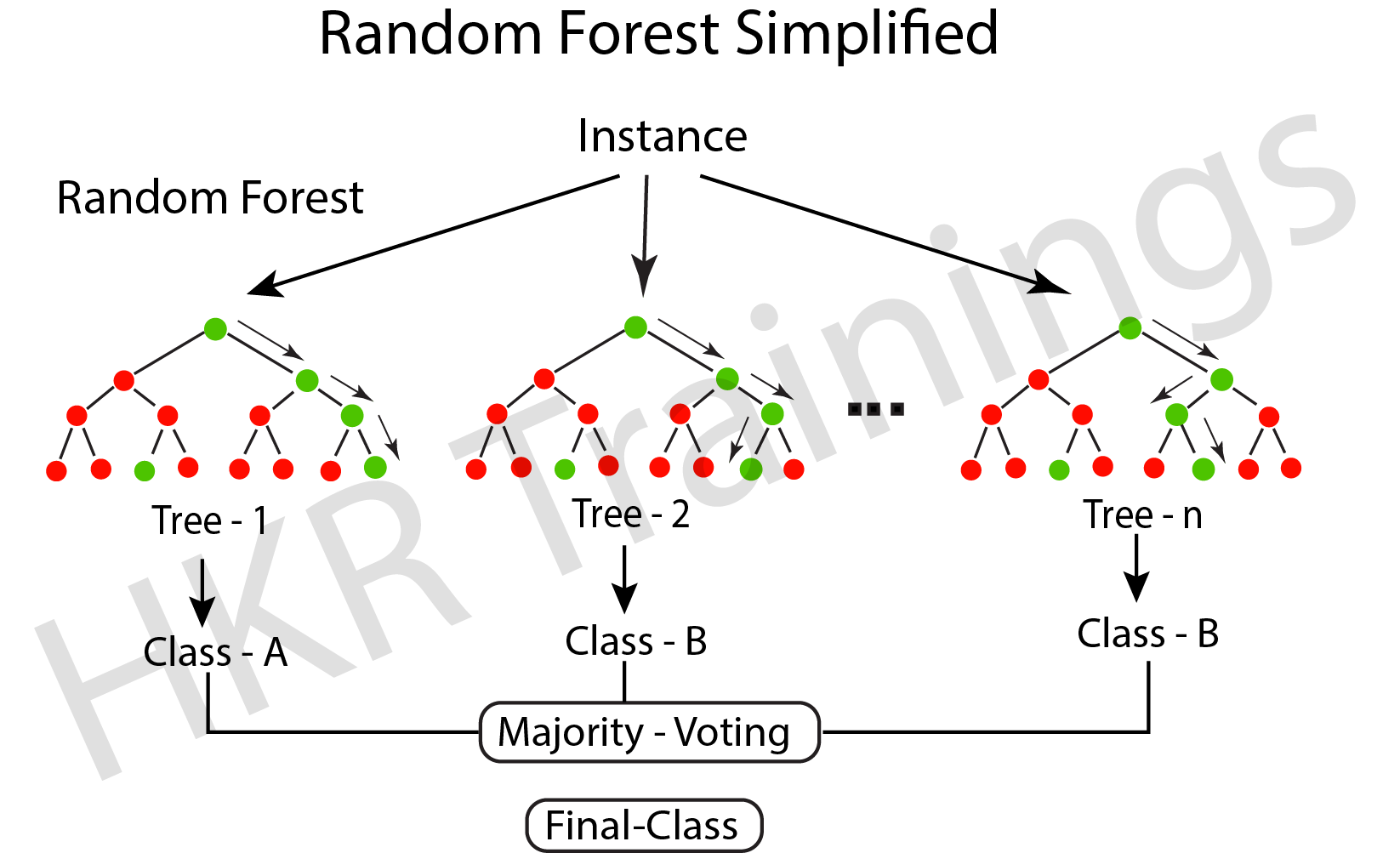
Random Forest
Random decision trees, also known as random forest, may be used for classification, regression, and other tasks. It works by building many decision trees during training and then outputs the class that is the individual trees’ mode, mean, or classification prediction.
A random forest (meta-estimator) fits several trees to different subsamples of data sets and averages the results to increase the model’s predicted accuracy. The sub-sample size is similar to the original input size; however, replacements are frequently used in the samples.
Artificial Neural Networks
A neural network uses a model inspired by neurons and their connections in the brain to convert an input vector to an output vector. The model comprises layers of neurons coupled by weights that change the relative relevance of different inputs. Each neuron has an activation function that controls the cell’s output (as a function of its input vector multiplied by its weight vector). The output is calculated by applying the input vector to the network’s input layer, then computing each neuron’s outputs via the network (in a feed-forward fashion).
Machine Learning Training
Weekday / Weekend Batches
Conclusion
In this blog, we looked at what Supervised Learning is and its sub-branch Classification, some of the most widely used classification models, and how to predict their accuracy and see whether they are trained correctly.
To provide the best experiences, we use technologies like cookies to store and/or access device information. Consenting to these technologies will allow us to process data such as browsing behavior or unique IDs on this site. Not consenting or withdrawing consent, may adversely affect certain features and functions.
Functional
Always active
The technical storage or access is strictly necessary for the legitimate purpose of enabling the use of a specific service explicitly requested by the subscriber or user, or for the sole purpose of carrying out the transmission of a communication over an electronic communications network.
Preferences
The technical storage or access is necessary for the legitimate purpose of storing preferences that are not requested by the subscriber or user.
Statistics
The technical storage or access that is used exclusively for statistical purposes.The technical storage or access that is used exclusively for anonymous statistical purposes. Without a subpoena, voluntary compliance on the part of your Internet Service Provider, or additional records from a third party, information stored or retrieved for this purpose alone cannot usually be used to identify you.
Marketing
The technical storage or access is required to create user profiles to send advertising, or to track the user on a website or across several websites for similar marketing purposes.