

Introduction to Cognos business intelligence
Cognos is an analytical platform mainly used in the development of an Artificial-based business intelligence tool. This business tool is developed to perform data aggregation methods, web-based integration, and to generate user-friendly analytical reports. Cognos is an Ontario-based company that supports business intelligence and performance development software. This tool also offers a medium to export the user-friendly data report in XML or PDF data formats, and also enables you to view the reports in XML format. Now we are using Cognos 8.2 version which is developed to support the eschool integrated reporting tool. This type of integrated tool provides predefined reporting, web-based reports to access real-time information, offers customizable for users to choose prompt values. One more important point about this Cognos tool is that this is a powerful ETL (extract, transfer, and load) tool, and supports designer graphical design environment engine server.
Cognos Overview
As I said earlier, Cognos is an IBM developed business intelligence tool, offering web-based reporting and analytic tools. This tool is used to create user-friendly reports which consist of graphs, different tab functionality, multiple pages, and interactive prompts. These reports are often viewed by users, and help to handle devices like smartphones and tabs. The Cognos also helps to export the reports in XML or PDF data formats files to view the reports in XML format. IBM Cognos business intelligence tool offers a wide range of data analytical features and they can be later considered as an enterprise software development tool to support flexible reporting environments (here you can consider both medium and large enterprises). These services should be the necessity of power users, business managers, analytic teams, and company executives. With the help of Cognos, power users, and business analysts to generate Ad-hoc reports and multiple times the same data views.
Interested in learning Cognos ? Join HKR and Learn more about Cognos integration Server Training!
Why do we need Cognos tools in business enterprises?
The following are the key factors that will explain why we need this business intelligence platform in any enterprise. Let me list few advantages of using Cognos;
1. This Cognos tool enables IT to focus on data management systems and offers enterprise-wide reporting and also delegates some report writing to business users.
2. The robust drill-down and visualization tools make data approachable for all types of users.
3. This business intelligence tool also improves productivity.
4. Combines the governed data with local data, calculations, formatting, and commentary.
5. Easy to refer to multiple data sources in data in a single workbook and provides a single sheet in some cases.
6. Business users can overcome technical challenges and authoring by leveraging excel skills.
7. Cognos is an Oracle-based model and provides standard reporting, ad-hoc reporting, report output, and scheduling.
8. Platform support tool: Windows, Linux, MAC, and web-based platform.
9. Predictive analysis and big data services.
Cognos architecture overview:
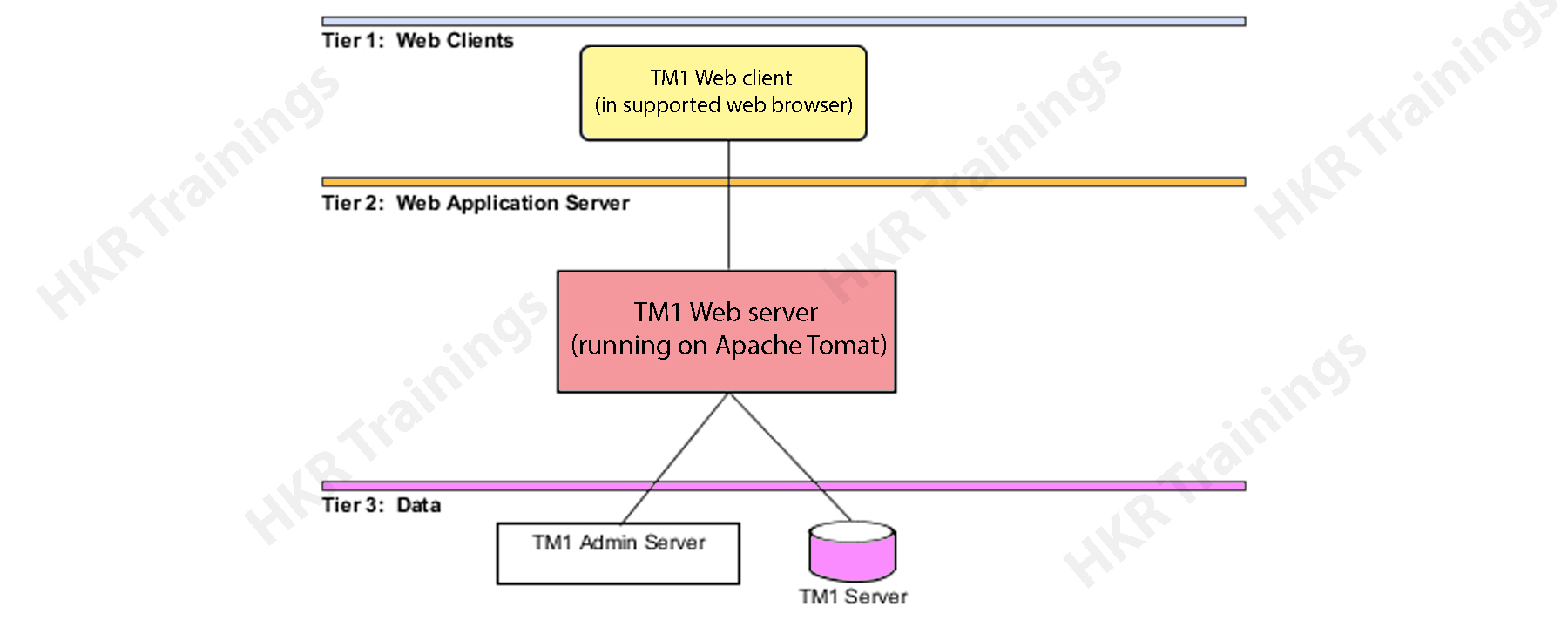
The Cognos architecture will explain the basic functionalities, working process, and types of architecture tires. The following diagram explains the scenarios:
Cognos Business intelligence tool is considered to be a 3-tier architecture type. At the top of the layout, you can see a web-client or a web server. The 2-tier consists of only a web application server, while the bottom tier consists of a data layer. These three tiers are separated by different firewalls and also establish communication between them. These can happen with the help of protocols like SOAP (simple object access protocol) and HTTP protocols.
Now it’s time to know them one by one:
Tier 1 web client:
This Web client allows business intelligence to access various data types and interact with multiple servers in any browser type. Tier 1 is also responsible to manage the system gateway and also perform the encryption and decryption process. This type of authorization process can be of many types like password, and extraction of information in the Business intelligence server.
Tier 2 Web application server:
This type of tier hosts the Cognos business intelligence server and associated services. It consists of components like Application tier components, Bootstrap services, and Content manager. The web application server runs only on JAVA based Apache Tomcat server. With the help of this tier, the Microsoft Excel worksheets will be converted into web sheets and perform exporting them to excel or PDF data formats.
Tier 3 database server:
This database server consists of contents and data source management. Tier 3 also consists of admin servers and TM servers. The admin server will be installed on any computer device using LAN connectivity. This connectivity resides on the same network server.

Cognos Training Certification
- Master Your Craft
- Lifetime LMS & Faculty Access
- 24/7 online expert support
- Real-world & Project Based Learning
Cognos – Components and services:
There are various components available in the Cognos and used to communicate with multiple devices by using Business Intelligence Bus known as SOAP (simple object access protocol) and supports WSDL. In normal, the business intelligence bus in Cognos architecture is not a type of software component but comprises a set of protocols for better communications.
The following are the important services included are:
1. Messaging and dispatching
2. Log message processing type
3. Database connection management
4. Microsoft .NET framework interaction
5. Port usage system
6. Request flow process
7. Portal usage.
The key components of Cognos are:
1. Gateway:
The Cognos web server consists of one or more gateways. Usually, these gateways are used to establish communications between one or more web servers. A gateway is just an extension of any web server program that helps in the transferring from one web server to another server. Web communication also occurs directly within a Cognos with less common options available.
There several types of web gateways you can find in the Cognos;
1. CGI = this is a default gateway and used to support web servers. This increases the performances and you can choose any gateway types with the help of CGI.
2. ISAPI = this is used for the Microsoft Internet Services (IIS) and delivers faster performance.
3. Apache_mod = you can make use of this Apache_mod gateway with the Apache Tomcat web server.
4. Servlet = this is a kind of Web server infrastructure that supports the servlets and here we use the application server as a Servlet gateway.
2. Application tier components:
This Cognos component consists of a dispatcher to operate different services and route requests. The dispatcher is a multithreaded application that makes use of one or more threads per HTTP request. If you make any changes to the configuration, all the running dispatches start communicating with each other. The dispatcher can also establish route requests to a local service, for example, report service, job service, monitor service, and presentation server.
3. Content manager:
The content manager consists of access management; this is a primary security component available in Cognos. Access manager leverages the already existing security providers and offers a consistent set of security capabilities. With the help of a content manager, you are able to access the Application programming interface, user authentication, encryption, and Authorization process. It also helps to create the Cognos namespace.
Cognos connections:
Here, users can report interactive user reports in Cognos Business intelligence studio on top of various data sources by creating a relational database and OLAP web connection in the web administration interface for data modeling in the framework manager is called Packages. Here all the reports and dashboards will be created in Cognos studios. The reports are later used to run complex report types and to view the BI or business intelligence information or this can also access different portals and also publish them on the studio. These types of Cognos connections are used to access queries, analysis, reports, and packages. They also can be used to create URLs, web pages, report shortcuts, and organize entities.
The following diagram explains the Cognos connection

a. Connecting different data sources:
What do you know about data sources? Here we are going to explain the data source definition. A data source specifies any physical connection to the database server and different connection parameters such as database location, connection timeout, and generating the request. Any data source connection consists of credentials and signs in detail. Here user can also create a new database connection, edit an already existing data source connection. Here you can also merge one or more data source connections, create new packages, and publish them with the help of the framework manager.
b. The dynamic query mode:
The dynamic query mode mainly used to offer better communication between different data sources with the help of XMLA/java connections. To connect with any relational database, you can make use of a type4 JDBC connection and these connections convert JDBC calls into a vendor-specific format. This JDBC calls format offers improved type 2 driver connectivity. Due to this reason, there is no need to convert data calls to ODBC (Object database connectivity) or any database API. A dynamic query mode in Cognos supports the following types of relational databases.
1. Microsoft SQL database server
2. Oracle database
3. IBM database 2
4. Teradata system
5. Netezza
To support the OLAP database source, both java and XMLA data connectivity offers enhanced and scalable MDX for various OLAP versions and technology. The Dynamic query mode can also be used with the various OLAP data sources:
a. SAP BI (business information) warehouse
c. Microsoft analytical services
d. IBM Cognos TM1
e. IBM Cognos real-time monitoring
DB2 data sources:
In general, the DB2 connection types are used to Connect DB2 windows, UNIX, and Linux, operating system platforms.
The common connection parameters used in DB2 data sources included are
1. Database name
2. Timeouts system
3. Sign on management
4. DB2 connect string
5. Collation sequence management
Data Source Security set up:
Data source security can be specified by using the IBM Cognos authentication environment. As per the data source system, different authentication will be configured in the Cognos connection.
1. No authentication: This connection allows users to login into the data source without using single sign-on credentials. This type of connection will not provide any data source security.
2. IBM Cognos software service is very credential: In this type of single sign-on method, first, you need to log into the data source management to access IBM Cognos service, and here the user does not require a separate database single sign-on system. In any live environment, it’s always good to use individual database sign-on.
3. External namespace: This requires the same business intelligence logon for the credentials to authenticate the external authentication namespace. Here the user must be logged into the IBM Cognos system with the help of namespace before logging into the data source and that should be active.
The following diagram explains this;

Here all the data source system also supports data source single sign-on specification for individual users, groups, and roles. If the data source requires any data source sign-on, then you will be prompted to access each data source. IBM Cognos also offers security at the cube levels.
Subscribe to our YouTube channel to get new updates..!
Cognos packages used:
In this section, we will be explaining how to create Packages in Cognos:
First step:
How to create a package?
In IBM Cognos, users can create packages for SAP business warehouse or any power cube data source system. Here the packages are located in the public folder as shown in the screenshot:

Once the package is deployed, the default configuration will be applied to the package. Here you can configure the package by using different settings and you need to modify the settings.
One point to remember, to configure a package, you should contain the administrator privilege.
First, you need to package in the public folder -> then click on more buttons -> which come under the action tab as shown below in the following screenshot.

Now click on the button to modify the package configuration -> click on select to analyze. Now it’s time to select the default analysis which is used to define packages -> then the new analysis is generated. Click Ok -> then change the package settings -> then click “Finish”.
Now it’s time to create a package:
Go to the package tab in the public folder -> then create a new package by using IBM Cognos connection.

Select the data source -> you need to use it in the package -> click OK.
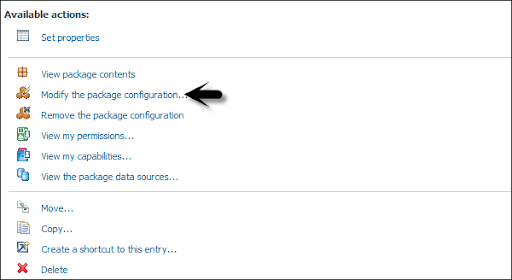
Schedule the reports in IBM Cognos:
Here users can also schedule the various reports in IBM Cognos as per the business requirements. Now schedule the report, that allows the user to save the refresh time source-> then you can also define the various scheduling package properties like time zone, start/ end date, and frequency.
To schedule any report -> select the report-> to go to more button as shown in the below screenshot:

You got an option -> then add a new schedule -> now select the new schedule button as shown below:

Here user can select the following methods under the new schedule tab:
1. Frequency
2. Start/end date
3. Priorities
4. Daily frequency set up.
When you define the scheduling property -> you can save it by using the OK button at the bottom tab. Now disable the schedule option -> that will allow users to make any schedule inactive -> but this schedule will be saved on the report.
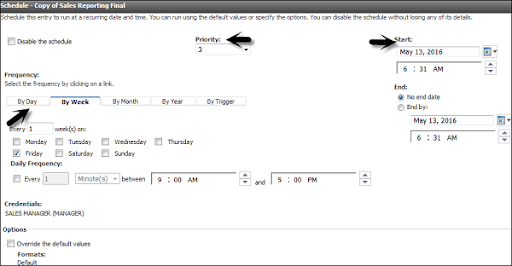
To edit an existing schedule -> you need to select the report -> to go to more. Here you can also modify an existing schedule time or remove it permanently.

Cognos Training Certification
Weekday / Weekend Batches
Cognos Framework manager overview:
IBM Cognos framework manager is mainly used to generate a business model of metadata that is derived from one or more data source management. This is a window based tool that is generally used to publish business models to manage the Cognos Business intelligence tool. The Cognos framework consists of packages mainly used for analytical reporting and data analysis purposes.
The fundamental concepts you should follow before you start with Framework manager:
1. Data source which is required to meet Business Intelligence needs.
2. The types of data warehouse systems used.
3. Data refresh in data warehouse management.
4. Business Intelligence reporting – which is available on a daily, weekly, or monthly basis.
Metadata modeling:
A metadata model specifies the collection of various database objects such as tables, columns, and also establishes relationships between the objects. Once you run the report, the metadata published in the business intelligence Cognos portal creates a SQL statement based on the query.
The following diagram explains the framework modeling:

IBM Cognos framework manager user interface:
This framework consists of the following components such as:
1. Project viewer details: This locates on the left side that allows the user to access all the already existing projects in a tree format.
2. Project information: This is available at the center pane used to manage data objects of an existing project. This consists of three tabs such as Explorer, diagram, and dimension view.
3. Properties details: This pane locates at the bottom which is used to set the value for various properties of an object in any project.
4. Tools used: this is located on the right side of the project that provides you the various important useful tools. Here user (you) can perform operations like search, display, or modify already existing objects.
Modelling Relational metadata:
Here once the user imports the metadata, the next step is to validate the object to perform reporting requirements. Users can also select the object that appears in the reporting and testing them. User can create two types of views in the metadata model:
1. Import view
2. Business view
The import view shows whether the metadata is imported from the various data sources. To perform validation of the data you have to perform the following steps:
1. You need to ensure the relationships reflect the reporting requirements.
2. Next step is to optimize and customize the data retrieval from the query subjects.
3. Optimize and customize the data retrieval by business model dimensions. Here you need to store the dimensions in a separate dimensional view.
4. Supporting the multilingual metadata handle.
5. Control how data will be used and those are formatted by verifying the query item properties.
The business view is used to offer the metadata information. With the help of this business view, you can perform operations like calculations, data aggregations, and applying the filters. And also you are able to build the reports easily by using a business view.
Cognos Query studio:
The Query studio is defined as the web based tool for creating the reports and queries in Cognos. This query studio is also used to run simple queries and reports.
1. Viewing the data:
Using the query studio, the user can connect the data source to view the data in a Cognos business tree hierarchy. Here you are able to see query subjects, item details, and query information.
2. Create the BI reports:
Here you can use a query studio to create simple query reports with the help of a data source. You are able to refer to already existing reports to generate a new report.
3. Changing the Existing reports:
You can also change the already existing data reports just by editing the various report layouts such as – Add charts, border styles, titles, and headings.
4. Data customization in reports:
Users can apply different customization techniques in reports, calculations, aggregations, and filters to perform operations like data analysis, drill down, and drill up methods.
Wish to make a career in the world of Cognos? Start with HKR’S Cognos Cube Training !
Cognos Ad hoc generation:
With the help of ad-hoc reporting, a user can generate data queries and reports to perform analysis. Ad-hoc reporting allows business users to generate simple types of data queries, reports, and dimension tables in DW (data warehouse).
This Query studio in Cognos Business intelligence offers the following features:
1. View the data queries and perform ad hoc data analysis features.
2. Save the reports for any future use.
3. Always helps to work with data in the given report just by applying filters, calculations, and summaries.
4. To create any ad-hoc report you have to follow the navigation; go to query studio -> login to IBM Cognos software-> click on a query on my data as shown in the following screenshot:

Then you have to -> select the report packages. Next time if you want to visit the same page -> you have to see the “selection” under recently used packages -> then click on the package’s name.

In the next screen -> you can add dimension elements, calculations, filters, and prompts.

Here you should insert the objects in order wise. To insert any object in the report -> here you have to use the insert button at the bottom of the query studio screen.
Below is the additional information you can use:
1. Inserting and filtering of the dimension elements.
2. Insertion of filters and prompts.
3. Insert the facts and calculations.
4. Applying the finishing touches.
5. Save, run, share, and collaborate.
At the top toolbar, you can create a new report, save the existing report, paste, cut, insert charts, drill up, and drill down, etc., as shown in the below screenshot.

Cognos Report types:
Here you can make use of different report types in the query studio to meet the business requirements while developing a product. The following are the key report types used in Cognos:
1. List reports: These types of reports are used to define the entire customer base requirements.
2. Cross tab reports: these reports are used to show product quantity sold out and different regions on a different axis.
3. Charts reports: here with the help of this report you can insert charts to show the data graphically. Here you can also combine a chart with a cross tab, or with a list of reports.
Filters calculations and their parameters:
Filters are used to limit the data type that is used in reports. You can also apply one or more filters while creating a Cognos reports and these reports will return the data items that meet the filter requirements or conditions. The following is the navigation to create custom filters in a report:
1. First you should select the column to filter.
2. Then click on the drop-down list -> from the filter button.
3. Now select the create custom filter button.
4. Then you will see the custom conditioning dialog window.
Filters parameters:
1. Condition: to get the condition parameter -> click on the list arrow to see your own choices.
2. Values: to get this parameter -> click on the list arrow to select your choices.
3. Keywords: This parameter allows the user to search for the specific data values available within the list.
4. Values list: with the help of this parameter user can make use of filter values -> then you can choose one or more data values -> then use the arrow buttons -> then click on add multiple values.
Conclusion:
I hope from this cognos tutorial, you may get some idea about how this business intelligence tool can be implemented and its features. This tutorial is best suited for those who are interested to learn data warehouse and visualization methods. The Cognos is emerging as a popular business intelligence tool due to its few major advantages like easy to use, learn, and perform various functionalities. Learning this tutorial will help you to master the few concepts of Cognos and get into a higher position when it comes to the profession.
Related Article:
Cognos Interview Questions

Stephan is the sports journalist for the Maple Grove Report.





