Premium credit cards can unlock luxury perks, airport lounge access and high-value rewards, but they can also come with hefty annual fees and a laundry list of benefits. So how do you know which one is actually worth it?
To help you decide, we’ve compared some of the top premium rewards cards across the factors that matter most — from welcome offers and earning rates to lounge access and statement credits — so you can find the right fit for your travel habits and spending style.
Here are the nine premium credit cards included in our comparison:
Methodology for comparing the best premium credit cards
For this comparison, we’ll compare these cards across seven categories:
Annual fee
Current welcome offer
Potential to earn points
Redemption options
Statement credits and notable perks
Lounge access
Travel and purchase protections
This analysis is based on an everyday traveler trying to decide which one of these cards is right for them. Since premium credit cards offer different perks and benefits, the card that’s right for your wallet depends on your specific needs.
Comparison of the best premium cards
Card
Annual fee
Additional cardholder fee
Welcome offer
Welcome offer value*
Earnings
Find out your offer and see if you are eligible for as high as 175,000 bonus points after spending $12,000 on purchases within the first six months of card membership. Welcome offers vary, and you may not be eligible for an offer.
Up to $3,500
5 points per dollar spent on airfare purchases booked through the airline or American Express Travel® (on up to $500,000 of these purchases per calendar year, then 1 point per dollar spent)
5 points per dollar spent on prepaid hotels booked through Amex Travel
1 point per dollar spent on other eligible purchases
$175 annual fee for the first three authorized users; $175 for each authorized user after that
Earn 70,000 bonus miles after spending $7,000 on purchases in the first three months of account opening.
$1,330
10 miles per dollar spent on eligible hotels booked through aa.com/hotels and eligible car rentals booked through aa.com/cars
4 miles per dollar spent on eligible American Airlines purchases
1 mile per dollar spent on all other purchases
$595
$75 per additional cardholder
Earn 75,000 bonus points after spending $6,000 on purchases in the first three months from account opening.
$1,425
12 points per dollar spent on hotels, car rentals and attractions booked through Citi Travel
6 points per dollar spent on air travel booked through Citi Travel
6 points per dollar spent at restaurants, including restaurant delivery services, on CitiNights℠ purchases every Friday and Saturday from 6 p.m. to 6 a.m. Eastern time; earn 3 points per dollar spent on dining any other time
1.5 points per dollar spent on all other purchases
Find out your offer and see if you are eligible for as high as 100,000 bonus miles after spending $5,000 on purchases in the first six months of card membership. Welcome offers vary, and you may not be eligible for an offer.
Up to $1,200
3 miles per dollar spent on eligible Delta purchases
1 mile per dollar spent on other eligible purchases
Earn 150,000 bonus points after spending $6,000 on purchases in the first six months of card membership.
$600
14 points per dollar spent at Hilton portfolio properties worldwide
7 points per dollar spent on flights booked directly with the airline or through Amex Travel
7 points per dollar spent on car rentals booked directly from select car rental companies
7 points per dollar spent at U.S. restaurants (including takeout and delivery)
3 points per dollar spent on other eligible purchases
Earn 200,000 bonus points after spending $6,000 on purchases within the first six months of card membership. Offer ends May 13.
$1,600
6 points per dollar spent on eligible purchases at hotels participating in the Marriott Bonvoy program
3 points per dollar spent at restaurants worldwide and on airfare purchased directly with the airline
2 points per dollar spent on other eligible purchases
$695
$0 for each additional cardholder
Earn up to 110,000 bonus miles and 3,000 PQPs: Earn 100,000 bonus miles and 3,000 PQPs after spending $5,000 on purchases in the first three months from account opening. Plus, earn 10,000 bonus miles after adding an authorized user in the first three months from account opening.
Up to $1,485 (including the points from adding an authorized user; not including the value of the PQPs)
5 miles per dollar spent when you book directly with Renowned Hotels and Resorts for United® Cardmembers
5 miles per dollar spent on United purchases
2 miles per dollar spent on all other travel and dining purchases (including eligible delivery services)
1 mile per dollar spent on other purchases
*Welcome offer value is an estimated value based on TPG’s May 2026 valuations and is not provided by the issuer.
Annual fee
When evaluating a card’s annual fee, weigh the benefits and statement credits it offers to see whether the value justifies the cost. Some cards with high annual fees can provide so much value that you might still come out ahead.
Reward your inbox with the TPG Daily newsletter
Join over 700,000 readers for breaking news, in-depth guides and exclusive deals from TPG’s experts
Whether or not a card charges a fee for additional cardholders also matters. Several of the cards on our list don’t charge a fee for additional cardholders (though some limit the number of complimentary users you can add).
The Hilton Honors American Express Aspire Card allows authorized users to enjoy an up-to-$400 Hilton resort statement credit each calendar year (up to $200 semiannually).
Still, the Venture X is the winner in this category. First and foremost, its $395 annual fee is much lower than the rest of the crowd. Plus, you can add up to four authorized users for no additional charge.
But it is important to note that if your authorized user wants Capital One lounge access, you’ll need to pay $125 per person for up to four authorized users.
All the premium cards listed above come with lucrative welcome offers that can help get you closer to your next big trip.
Cards that earn transferable rewards for their welcome offers are worth more than their cobranded counterparts.
For example, with the Amex Platinum, you can find out your offer and see if you are eligible for as high as 175,000 bonus points after spending $12,000 on purchases within the first six months of card membership. Welcome offers vary, and you may not be eligible for an offer.
The Amex Platinum welcome offer is worth up to $3,500 based on TPG’s May 2026 valuations. That’s substantially more valuable than virtually any cobranded card’s welcome offer.
Another important aspect when comparing premium credit cards is the points-earning potential and the rewards you can earn.
The Sapphire Reserve, for example, comes out on top here. It offers one of the most valuable currencies for a wide variety of purchases. Chase Ultimate Rewards points are worth 2.05 cents apiece, according to TPG’s May 2026 valuations.
The Strata Elite also provides high earning rates when spending through its portal. Citi ThankYou Rewards points are worth slightly less than Ultimate Rewards points, at a 1.9 cents-per-point valuation per TPG’s May 2026 valuations.
Another important aspect when comparing premium cards is the redemption options. Generally, the card that provides the most value is the one that offers transfer partners.
Card
Redemption/transfer options
You can redeem points to book travel directly through Chase Travel; with the Points Boost perk, your points can be worth up to 2 cents apiece, depending on the specific redemption (see your rewards program agreement for full details).
You can redeem miles for flights on American Airlines and its various Oneworld alliance partners and non-alliance partners like Etihad Airways, as well as upgrades, hotels, rental cars, experiences and Admirals Club passes.
You can redeem miles for flights on Delta and its various SkyTeam or non-alliance partners like WestJet, as well as seat upgrades, Delta Vacations packages, Delta Stays, car rentals, SkyMiles experiences and magazines.
All these premium card options offer statement credits and perks designed to provide value to cardholders. In some cases, if you use the full value of these credits and perks, you can recover your annual fee. In some cases, you might even come out ahead.
Card
Statement credits and benefits
Up to $600 in prepaid hotel statement credits for eligible Fine Hotels + Resorts or The Hotel Collection bookings per calendar year through Amex Travel (up to $300 semiannually)
Up to $400 Resy statement credit per calendar year (allotted up to $100 quarterly) when you pay with your card at participating U.S. Resy restaurants
Up to $300 per calendar year in Lululemon statement credits at U.S. Lululemon retail stores (excluding outlets) and lululemon.com (allotted up to $75 quarterly)
Up to $200 per calendar year (allotted up to $15 monthly, plus an up to $20 bonus in December) in Uber Cash (valid on U.S. purchases; add your Amex Platinum to your Uber account and redeem with any Amex card)
Up to $200 per calendar year in statement credits toward Oura Ring purchases (hardware only)
Up to $155 per calendar year (allotted up to $12.95 monthly) in statement credits for one Walmart+ membership (Plus Ups are excluded)
$120 Global Entry or up to $85 TSA PreCheck application fee statement credit (once every four years for Global Entry or every 4 1/2 years for TSA PreCheck)
Up to $120 per calendar year toward an annual Uber One membership
Up to $300 annual StubHub and Viagogo credit (allotted $150 biannually) through Dec. 31, 2027; activation required
Up to $300 annual dining credit at OpenTable
Up to $300 annual value with DoorDash: Cardholders receive up to $25 in monthly promos with two $10 nonrestaurant promos and one $5 restaurant promo, plus a complimentary DashPass membership for at least one year (must activate by Dec. 31, 2027)
Up to $288 annually in complimentary Apple TV and Apple Music subscriptions (one-time activation per service through chase.com or Chase Mobile app required; subscriptions run through June 22, 2027)
Up to $120 annual in-app Lyft credits (allotted up to $10 monthly; through Sept. 30, 2027); credit does not apply to Wait & Save, bike or scooter rides
Up to $120 Peloton credit ($10 monthly; through Dec. 31, 2027; activation required)
Up to $120 Global Entry, TSA PreCheck or Nexus application fee statement credit (once every four years)
Up to $120 in Lyft credits; after taking three eligible rides in a calendar month, you will earn a $10 Lyft credit (for a total of up to $120 Lyft credits annually)
Up to $120 back on Grubhub purchases as a statement credit of up to $10 per monthly billing statement on eligible Grubhub purchases (for a total of up to $120 for every 12 billing statements)
Up to $120 back in statement credits per calendar year on Avis or Budget car rentals as a statement credit on eligible prepaid Avis or Budget car rentals booked directly
Up to $120 Global Entry or TSA PreCheck application fee statement credit (once every four years)
Free checked bag on domestic flights and 25% off of inflight food-and-beverage purchases
Up to $300 annually on prepaid hotel stays booked with Citi Travel (minimum two-night stay required)
Up to $200 annually in Splurge credits for choice of up to two of the following brands: 1stDibs (selling luxury art, furniture and jewelry), American Airlines, Best Buy, Future Personal Training and Live Nation (exclusions apply)
Up to $200 annually for Blacklane private chauffeur service (split into $100 biannually)
Up to $120 Global Entry or TSA PreCheck application fee statement credit (once every four years)
Up to $240 Resy statement credit per calendar year (allotted up to $20 monthly) when you pay with your card at participating U.S. Resy restaurants
Up to $120 ride-hailing statement credit per calendar year (allotted up to $10 monthly) when you use your card at select ride-hailing providers in the U.S.
$120 Global Entry or up to $85 TSA PreCheck application fee statement credit (once every four years)
Free checked bag
Upgrade priority and being placed on the complimentary upgrade list
20% off in-flight purchases (in the form of a statement credit)
TakeOff15 (a 15% discount on Delta award flight redemptions)
Hertz President’s Circle status (enrollment in the Hertz Gold Plus Rewards program is required)
Annual companion certificate
Enrollment is required for select benefits.
Up to $400 Hilton resort statement credit per calendar year (allotted up to $200 semiannually)
Up to $200 flight statement credit per calendar year (allotted up to $50 quarterly) for flights booked directly or through amextravel.com
Up to $209 Clear+ membership statement credit per calendar year (subject to auto-renewal)
Up to $100 in on-property credit for two-night Waldorf Astoria or Conrad stays
Free night certificate upon account opening and a free night certificate on each cardmember anniversary
Avis President’s Club elite status (enrollment required)
**Upon enrollment, accessible through the Capital One website or mobile app, eligible cardholders will remain at that status level through the duration of the offer. Note that enrolling through the normal Hertz Gold Plus Rewards enrollment process (e.g., at hertz.com) will not automatically detect a cardholder as being eligible for the program, and cardholders will not be automatically upgraded to the applicable status tier. Additional terms apply.
Analysis
The Amex Platinum has a slew of benefits; if you can maximize them, you will more than offset the card’s annual fee. However, the value they can provide in your situation can vary.
The Sapphire Reserve also offers a lot of value. The card’s best benefit is its $300 travel credit, which is higher than most competitors’ and applies to any travel purchase (as opposed to just fees or airfare, like some of its competition).
The Strata Elite provides some credits and benefits to help offset its annual fee, but they aren’t as plentiful or useful as other premium cards.
The Venture X also has a $300 travel credit, though it’s more limited: It only applies to bookings made through Capital One Travel. On the plus side, with the 10,000 anniversary bonus miles and the full value of the travel credit, you can net positive value every year.
The cobranded hotel cards offer substantial value when staying at Hilton or Marriott properties, plus useful hotel-related statement credits and benefits like elite status and free night awards.
The cobranded airline cards provide modest statement credits, but the in-flight discounts and free checked bags can be very useful if you frequently fly on one of those airlines.
Delta Sky Clubswhen flying Delta or a Delta-marketed flight operated by WestJet
Eligible cardmembers will receive 10 visits per year to the Delta Sky Club; to earn an unlimited number of visits each year, cardmembers must spend $75,000 or more in a year; basic economy tickets are not eligible for entry
All these cards also provide various coverages and protections when you’re traveling or making purchases, which can make your life easy if things go awry. They all have some combination of the following protections and insurance:
Analysis
The Sapphire Reserve is the best premium credit card here, with its slew of protections like primary car rental insurance, emergency evacuation insurance and travel accident insurance.
The Venture X comes in second, thanks to fairly comprehensive protections that include cellphone coverage.
The Amex Platinum offers significant travel insurance coverage***, but note that the rental car benefit provides secondary coverage**** and there is no baggage delay coverage.
While many of these benefits look similar overall, your best bet is to examine the differences between policies and determine how likely those are to affect your trips. All of these cards offer various protections and insurances, so analyze what is best for your needs.
***Terms, conditions and limitations apply for travel insurances and protections. Visit americanexpress.com/benefitsguide for details.
****Eligibility and benefit level varies by card. Not all vehicle types or rentals are covered, and geographic restrictions apply. Terms, conditions and limitations apply. Visit americanexpress.com/benefitsguide for details. Policies are underwritten by AMEX Assurance Company. Coverage is offered through American Express Travel Related Services Company, Inc.
With high annual fees and a wide range of benefits, the key is focusing on the features you’ll use most — whether that’s lounge access, statement credits or rewards earning.
For Capital One products listed on this page, some of the benefits may be provided by Visa® or Mastercard® and may vary by product. See the respective Guide to Benefits for details, as terms and exclusions apply.
For rates and fees of the Amex Platinum Card, click here. For rates and fees of the Delta SkyMiles Reserve American Express Card, click here. For rates and fees of the Marriott Bonvoy Brilliant American Express Card, click here. For rates and fees of the Hilton Honors Aspire, click here.
The quant finance industry has spent decades building specialized models for every conceivable forecasting task: GARCH variants for volatility, ARIMA for mean reversion, Kalman filters for state estimation, and countless proprietary approaches for statistical arbitrage. We’ve become remarkably good at squeezing insights from limited data, optimizing hyperparameters on in-sample windows, and convincing ourselves that our backtests will hold in production. Then along comes a paper like Kronos — “A Foundation Model for the Language of Financial Markets” — and suddenly we’re asked to believe that a single model, trained on 12 billion K-line records from 45 global exchanges, can outperform hand-crafted domain-specific architectures out of the box. That’s a bold claim. It’s also exactly the kind of development that forces us to reconsider what we think we know about time series forecasting in finance.
The Foundation Model Paradigm Comes to Finance
If you’ve been following the broader machine learning literature, foundation models will be familiar. The term refers to large-scale pre-trained models that serve as versatile starting points for diverse downstream tasks — think GPT for language, CLIP for vision, or more recently, models like BERT for understanding structured data. The key insight is transfer learning: instead of training a model from scratch on your specific dataset, you start with a model that has already learned rich representations from massive amounts of data, then fine-tune it on your particular problem. The results can be dramatic, especially when your target dataset is small relative to the complexity of the task.
Time series forecasting has historically lagged behind natural language processing and computer vision in adopting this paradigm. Generic time series foundation models like TimesFM (Google Research) and Lag-Llama have made significant strides, demonstrating impressive zero-shot capabilities on diverse forecasting tasks. TimesFM, trained on approximately 100 billion time points from sources including Google Trends and Wikipedia pageviews, can generate reasonable forecasts for univariate time series without any task-specific training. Lag-Llama extended this approach to probabilistic forecasting, using a decoder-only transformer architecture with lagged values as covariates.
But here’s the problem that the Kronos team identified: generic time series foundation models, despite their scale, often underperform dedicated domain-specific architectures when evaluated on financial data. This shouldn’t be surprising. Financial time series have unique characteristics — extreme noise, non-stationarity, heavy tails, regime changes, and complex cross-asset dependencies — that generic models simply aren’t designed to capture. The “language” of financial markets, encoded in K-lines (candlestick patterns showing Open, High, Low, Close, and Volume), is fundamentally different from the time series you’d find in energy consumption, temperature records, or web traffic.
Enter Kronos: A Foundation Model Built for Finance
Kronos, introduced in a 2025 arXiv paper by Yu Shi and colleagues from Tsinghua University, addresses this gap directly. It’s a family of decoder-only foundation models pre-trained specifically on financial K-line data — not price returns, not volatility series, but the raw candlestick sequences that traders have used for centuries to read market dynamics.
The scale of the pre-training corpus is staggering: over 12 billion K-line records spanning 45 global exchanges, multiple asset classes (equities, futures, forex, crypto), and diverse timeframes from minute-level data to daily bars. This is not a model that has seen a few thousand time series. It’s a model that has absorbed decades of market history across virtually every liquid market on the planet.
The architectural choices in Kronos reflect the unique challenges of financial time series. Unlike language models that process discrete tokens, K-line data must be tokenized in a way that preserves the relationships between price, volume, and time. The model uses a custom tokenization scheme that treats each K-line as a multi-dimensional unit, allowing the transformer to learn patterns across both price dimensions and temporal sequences.
What Makes Kronos Different: Architecture and Methodology
At its core, Kronos employs a transformer architecture — specifically, a decoder-only model that predicts the next K-line in a sequence given all previous K-lines. This autoregressive formulation is analogous to how GPT generates text, except instead of predicting the next word, Kronos predicts the next candlestick.
The mathematical formulation is worth understanding in detail. Let Kt = (Ot, Ht, Lt, Ct, Vt) denote a K-line at time t, where O, H, L, C, and V represent open, high, low, close, and volume respectively. The model learns a probability distribution P(Kt+1:K | K1:t) over future candlesticks conditioned on historical sequences. The transformer processes these K-lines through stacked self-attention layers:
where the query, key, and value projections are learned linear transformations of the input representations. The attention mechanism computes:
allowing the model to weigh the relevance of each historical K-line when predicting the next one. Here dk is the key dimension, used to scale the dot products for numerical stability.
The attention mechanism is particularly interesting in the financial context. Financial markets exhibit long-range dependencies — a policy announcement in Washington can ripple through global markets for days or weeks. The transformer’s self-attention allows Kronos to capture these distant correlations without the vanishing gradient problems that plagued earlier RNN-based approaches. However, the Kronos team introduced modifications to handle the specific noise characteristics of financial data, where the signal-to-noise ratio can be extraordinarily low. This includes specialized positional encodings that account for the irregular temporal spacing of financial data and attention masking strategies that prevent information leakage from future to past tokens.
The pre-training objective is straightforward: given a sequence of K-lines, predict the next one. This is formally a maximum likelihood estimation problem:
where θ represents the model parameters. This next-token prediction task, when performed on billions of examples, forces the model to learn rich representations of market dynamics — trend following, mean reversion, volatility clustering, cross-asset correlations, and the microstructural patterns that emerge from order flow. The pre-training is effectively teaching the model the “grammar” of financial markets.
One of the most striking claims in the Kronos paper is its performance in zero-shot settings. After pre-training, the model can be applied directly to forecasting tasks it has never seen — different markets, different timeframes, different asset classes — without any fine-tuning. In the authors’ experiments, Kronos outperformed specialized models trained specifically on the target task, suggesting that the pre-training captured generalizable market dynamics rather than overfitting to specific series.
Beyond Price Forecasting: The Full Range of Applications
The Kronos paper demonstrates the model’s versatility across several financial forecasting tasks:
Price series forecasting is the most obvious application. Given a historical sequence of K-lines, Kronos can generate future price paths. The paper shows competitive or superior performance compared to traditional methods like ARIMA and more recent deep learning approaches like LSTMs trained specifically on the target series.
Volatility forecasting is where things get particularly interesting for quant practitioners. Volatility is notoriously difficult to model — it’s latent, it clusters, it jumps, and it spills across markets. Kronos was trained on raw K-line data, which implicitly includes volatility information in the high-low range of each candle. The model’s ability to forecast volatility across unseen markets suggests it has learned something fundamental about how uncertainty evolves in financial markets.
Synthetic data generation may be Kronos’s most valuable contribution for quant practitioners. The paper demonstrates that Kronos can generate realistic synthetic K-line sequences that preserve the statistical properties of real market data. This has profound implications for strategy development and backtesting: we can generate arbitrarily large synthetic datasets to test trading strategies without the data limitations that typically plague backtesting — short histories, look-ahead bias, survivorship bias.
Cross-asset dependencies are naturally captured in the pre-training. Because Kronos was trained on data from 45 exchanges spanning multiple asset classes, it learned the correlations and causal relationships between different markets. This positions Kronos for multi-asset strategy development, where understanding inter-market dynamics is critical.
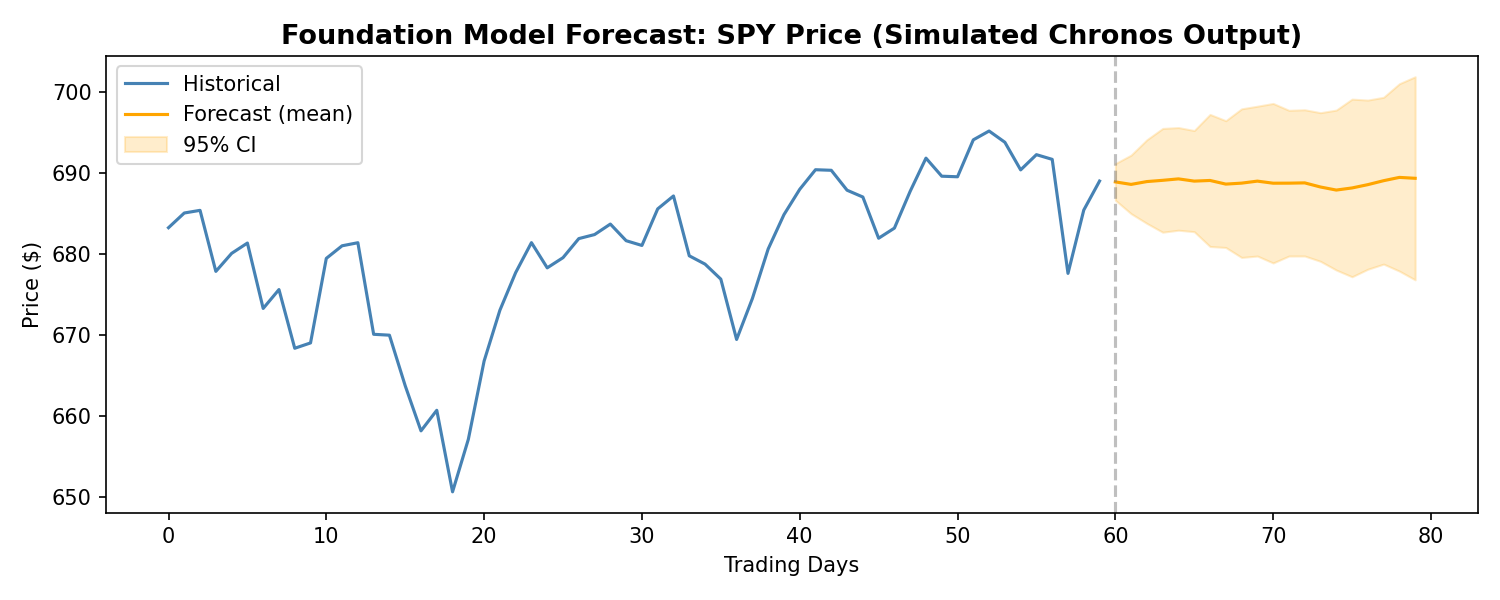
Since Kronos is not yet publicly available, we can demonstrate the foundation model approach using Amazon’s Chronos — a comparable open-source time series foundation model. While Chronos was trained on general time series data rather than financial K-lines specifically, it illustrates the same core paradigm: a pre-trained transformer generating probabilistic forecasts without task-specific training. Here’s a practical demo on real financial data:
import yfinance as yfimport numpy as npimport matplotlib.pyplot as pltfrom chronos import ChronosPipeline# Load model and fetch datapipeline = ChronosPipeline.from_pretrained("amazon/chronos-t5-large", device_map="cuda")data = yf.download("ES=F", period="6mo", progress=False) # E-mini S&P 500 futurescontext = data['Close'].values[-60:] # Use last 60 days as context# Generate forecastforecast = pipeline.predict(context, prediction_length=20)# Plotfig, ax = plt.subplots(figsize=(10, 4))ax.plot(range(60), context, label="Historical", color="steelblue")ax.plot(range(60, 80), forecast.mean(axis=0), label="Forecast", color="orange")ax.axvline(x=59, color="gray", linestyle="--", alpha=0.5)ax.set_title("Chronos Forecast: ES Futures (20-day)")ax.legend()plt.tight_layout()plt.show()
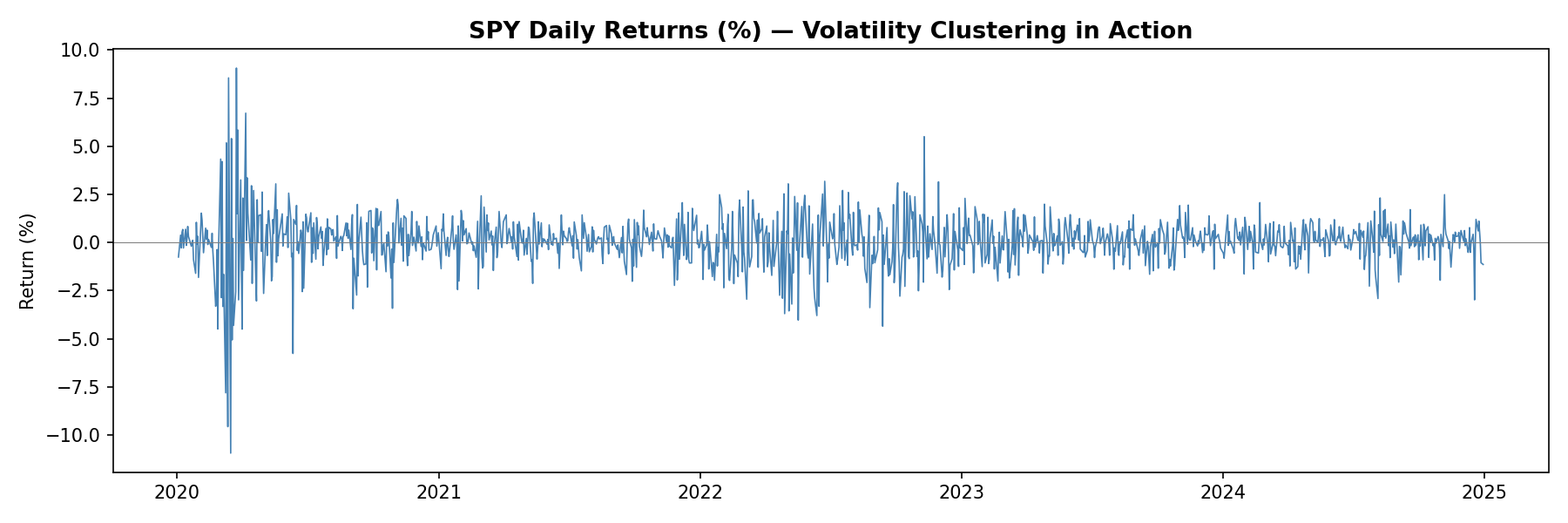
SPY Daily Returns — Volatility Clustering in Action
Zero-Shot vs. Fine-Tuned Performance: What the Evidence Shows
The zero-shot results from Kronos are impressive but warrant careful interpretation. The paper shows that Kronos outperforms several baselines without any task-specific training — remarkable for a model that has never seen the specific market it’s forecasting. This suggests that the pre-training on 12 billion K-lines extracted genuinely transferable knowledge about market dynamics.
However, fine-tuning consistently improves performance. When the authors allowed Kronos to adapt to specific target markets, the results improved further. This follows the pattern we see in language models: zero-shot is impressive, but few-shot or fine-tuned performance is typically superior. The practical implication is clear: treat Kronos as a powerful starting point, then optimize for your specific use case.
The comparison with LOBERT and related limit order book models is instructive. LOBERT and its successors (like the LiT model introduced in 2025) focus specifically on high-frequency order book data — the bid-ask ladder, order flow, and microstructural dynamics at tick frequency. These are fundamentally different from K-line models. Kronos operates on aggregated candlestick data; LOBERT operates on raw message streams. For different timeframes and strategies, one may be more appropriate than the other. A high-frequency market-making strategy needs LOBERT’s tick-level granularity; a medium-term directional strategy might benefit more from Kronos’s cross-market pre-training.
Connecting to Traditional Approaches: GARCH, ARIMA, and Where Foundation Models Fit
Let me be direct: I’m skeptical of any framework that claims to replace decades of econometric research without clear evidence of superior out-of-sample performance. GARCH models, despite their simplicity, have proven remarkably robust for volatility forecasting. ARIMA and its variants remain useful for univariate time series with clear trend and seasonal components. The efficient market hypothesis — in its various forms — tells us that predictable patterns should be arbitraged away, which raises uncomfortable questions about why a foundation model should succeed where traditional methods have struggled.
That said, there’s a nuanced way to think about this. Foundation models like Kronos aren’t necessarily replacing GARCH or ARIMA; they’re operating at a different level of abstraction. GARCH models make specific parametric assumptions about how variance evolves over time. Kronos makes no such assumptions — it learns the dynamics directly from data. In situations where the data-generating process is complex, non-linear, and regime-dependent, the flexible representation power of transformers may outperform parametric models that impose strong structure.
Consider volatility forecasting, traditionally the domain of GARCH. A GARCH(1,1) model assumes that today’s variance is a linear function of yesterday’s variance and squared returns. This is obviously a simplification. Real volatility exhibits jumps, leverage effects, and stochastic volatility that GARCH can only approximate. Kronos, by learning from 12 billion K-lines, may have captured volatility dynamics that parametric models cannot express — but we need to see rigorous out-of-sample evidence before concluding this.
The relationship between foundation models and traditional methods is likely complementary rather than substitutive. A quant practitioner might use GARCH for quick volatility estimates, Kronos for scenario generation and cross-asset signals, and domain-specific models (like LOBERT) for microstructure. The key is understanding each tool’s strengths and limitations.
Here’s a quick visualization of what volatility clustering looks like in real financial data — notice how periods of high volatility tend to cluster together:
Foundation Model Forecast: SPY Price (Chronos — comparable to Kronos approach)
Practical Implications for Quant Practitioners
For those of us building trading systems, what does this actually mean? Several practical considerations emerge:
Data efficiency is perhaps the biggest win. Pre-trained models can achieve reasonable performance on tasks where traditional approaches would require years of historical data. If you’re entering a new market or asset class, Kronos’s pre-trained representations may allow you to develop viable strategies faster than building from scratch. Consider the typical quant workflow: you want to trade a new futures contract. Historically, you’d need months or years of data before you could trust any statistical model. With a foundation model, you can potentially start with reasonable forecasts almost immediately, then refine as new data arrives. This changes the economics of market entry.
Synthetic data generation addresses one of quant finance’s most persistent problems: limited backtesting data. Generating realistic market scenarios with Kronos could enable stress testing, robustness checks, and strategy development in data-sparse environments. Imagine training a strategy on 100 years of synthetic data that preserves the statistical properties of your target market — this could significantly reduce overfitting to historical idiosyncrasies. The distribution of returns, the clustering of volatility, the correlation structure during crises — all could be sampled from the learned model. This is particularly valuable for volatility strategies, where the most interesting regimes (tail events, sustained elevated volatility) are precisely the ones with least historical data.
Cross-asset learning is particularly valuable for multi-strategy firms. Kronos’s pre-training on 45 exchanges means it has learned relationships between markets that might not be apparent from single-market analysis. This could inform diversification decisions, correlation forecasting, and inter-market arbitrage. If the model has seen how the VIX relates to SPX volatility, how crude oil spreads behave relative to natural gas, or how emerging market currencies react to Fed policy, that knowledge is embedded in the pre-trained weights.
Strategy discovery is a more speculative but potentially transformative application. Foundation models can identify patterns that human intuition misses. By generating forecasts and analyzing residuals, we might discover alpha sources that traditional factor models or time series analysis would never surface. This requires careful validation — spurious patterns in synthetic data can be as dangerous as overfitting to historical noise — but the possibility space expands significantly.
Integration challenges should not be underestimated. Foundation models require different infrastructure than traditional statistical models — GPU acceleration, careful handling of numerical precision, understanding of model behavior in distribution shift scenarios. The operational overhead is non-trivial. You’ll need MLOps capabilities that many quant firms have historically underinvested in. Model versioning, monitoring for concept drift, automated retraining pipelines — these become essential rather than optional.
There’s also a workflow consideration. Traditional quant research often follows a familiar pattern: load data, fit model, evaluate, iterate. Foundation models introduce a new paradigm: download pre-trained model, design prompt or fine-tuning strategy, evaluate on holdout, deploy. The skills required are different. Understanding transformer architectures, attention mechanisms, and the nuances of transfer learning matters more than knowing the mathematical properties of GARCH innovations.
For teams considering adoption, I’d suggest a staged approach. Start with the zero-shot capabilities to establish baselines. Then explore fine-tuning on your specific datasets. Then investigate synthetic data generation for robustness testing. Each stage builds organizational capability while managing risk. Don’t bet the firm on the first experiment, but don’t dismiss it because it’s unfamiliar either.
Limitations and Open Questions
I want to be clear-eyed about what we don’t yet know. The Kronos paper, while impressive, represents early research. Several critical questions remain:
Out-of-sample robustness: The paper’s results are based on benchmark datasets. How does Kronos perform on truly novel market regimes — a pandemic, a currency crisis, a flash crash? Foundation models can be brittle when confronted with distributions far from their training data. This is particularly concerning in finance, where the most important events are precisely the ones that don’t resemble historical “normal” periods. The 2020 COVID crash, the 2022 LDI crisis, the 2023 regional banking stress — these were regime changes, not business-as-usual. We need evidence that Kronos handles these appropriately.
Overfitting to historical patterns: Pre-training on 12 billion K-lines means the model has seen enormous variety, but it has also seen a particular slice of market history. Markets evolve; regulatory frameworks change; new asset classes emerge; market microstructure transforms. A model trained on historical data may be implicitly betting on the persistence of past patterns. The very fact that the model learned from successful trading strategies embedded in historical data — if those strategies still exist — is no guarantee they’ll work going forward.
Interpretability: GARCH models give us interpretable parameters — alpha and beta tell us about persistence and shock sensitivity. Kronos is a black box. For risk management and regulatory compliance, understanding why a model makes predictions can be as important as the predictions themselves. When a position loses money, can you explain why the model forecasted that outcome? Can you stress-test the model by understanding its failure modes? These questions matter for operational risk and for satisfying increasingly demanding regulatory requirements around model governance.
Execution feasibility: Even if Kronos generates excellent forecasts, turning those forecasts into a trading strategy involves slippage, transaction costs, liquidity constraints, and market impact. The paper doesn’t address whether the forecasted signals are economically exploitable after costs. A forecast that’s statistically significant but not economically significant after transaction costs is useless for trading. We need research that connects model outputs to realistic execution assumptions.
Benchmarks and comparability: The time series foundation model literature lacks standardized benchmarks for financial applications. Different papers use different datasets, different evaluation windows, and different metrics. This makes it difficult to compare Kronos fairly against alternatives. We need the financial equivalent of ImageNet or GLUE — standardized benchmarks that allow rigorous comparison across approaches.
Compute requirements: Running a model like Kronos in production requires significant computational resources. Not every quant firm has GPU clusters sitting idle. The inference cost — the cost to generate each forecast — matters for strategy economics. If each forecast costs $0.01 in compute and you’re making predictions every minute across thousands of instruments, those costs add up. We need to understand the cost-benefit tradeoff.
Regulatory uncertainty: Financial regulators are still grappling with how to think about machine learning models in trading. Foundation models add another layer of complexity. Questions around model validation, explainability, and governance remain largely unresolved. Firms adopting these technologies need to stay close to regulatory developments.
Finally, there’s a philosophical concern worth mentioning. Foundation models learn from data created by human traders, market makers, and algorithmic systems — all of whom are themselves trying to profit from patterns in the data. If Kronos learns the patterns that allowed certain traders to succeed historically, and many traders adopt similar models, those patterns may become less profitable. This is the standard arms race argument applied to a new context. Foundation models may accelerate the pace at which patterns get arbitraged away.
The Road Ahead: NeurIPS 2025 and Beyond
The interest in time series foundation models is accelerating rapidly. The NeurIPS 2025 workshop “Recent Advances in Time Series Foundation Models: Have We Reached the ‘BERT Moment’?” (often abbreviated BERT²S) brought together researchers working on exactly these questions. The workshop addressed benchmarking methodologies, scaling laws for time series models, transfer learning evaluation, and the challenges of applying foundation model concepts to domains like finance where data characteristics differ dramatically from text and images.
The academic momentum is clear. Google continues to develop TimesFM. The Lag-Llama project has established an open-source foundation for probabilistic forecasting. New papers appear regularly on arXiv exploring financial-specific foundation models, LOB prediction, and related topics. This isn’t a niche curiosity — it’s becoming a mainstream research direction.
For quant practitioners, the message is equally clear: pay attention. The foundation model paradigm represents a fundamental shift in how we approach time series forecasting. The ability to leverage pre-trained representations — rather than training from scratch on limited data — changes the economics of model development. It may also change which problems are tractable.
Conclusion
Kronos represents an important milestone in the application of foundation models to financial markets. Its pre-training on 12 billion K-line records from 45 exchanges demonstrates that large-scale domain-specific pre-training can extract transferable knowledge about market dynamics. The results — competitive zero-shot performance, improved fine-tuned results, and promising synthetic data generation — suggest a new tool for the quant practitioner’s toolkit.
But let’s not overheat. This is 2025, not the year AI solves markets. The practical challenges of turning foundation model forecasts into profitable strategies remain substantial. GARCH and ARIMA aren’t obsolete; they’re complementary. The key is understanding when each approach adds value. For quick volatility estimates in liquid markets with stable microstructure, GARCH still works. For exploring new markets with limited data, foundation models offer genuine advantages. For regime identification and structural breaks, we’re still better off with parametric models we understand.
What excites me most is the synthetic data generation capability. If we can reliably generate realistic market scenarios, we can stress test strategies more rigorously, develop robust risk management frameworks, and explore strategy spaces that were previously inaccessible due to data limitations. That’s genuinely new. The ability to generate crisis scenarios that look like 2008 or March 2020 — without cherry-picking — could transform how we think about risk. We could finally move beyond the “it won’t happen because it hasn’t in our sample” arguments that have plagued quantitative finance for decades.
But even here, caution is warranted. Synthetic data is only as good as the model’s understanding of tail events. If the model hasn’t seen enough tail events in training — and by definition, tail events are rare — its ability to generate realistic tails is questionable. The saying “garbage in, garbage out” applies to synthetic data generation as much as anywhere else.
The broader foundation model approach to time series — whether through Kronos, TimesFM, Lag-Llama, or the models yet to come — is worth serious attention. These are not magic bullets, but they represent a meaningful evolution in our methodological toolkit. For quants willing to learn new approaches while maintaining skepticism about hype, the next few years offer real opportunity. The question isn’t whether foundation models will matter for quant finance; it’s how quickly they can be integrated into production workflows in a way that’s robust, interpretable, and economically valuable.
I’m keeping an open mind while holding firm on skepticism. That’s served me well in 25 years of quantitative finance. It will serve us well here too.
Author’s Assessment: Bull Case vs. Bear Case
The Bull Case: Kronos demonstrates that large-scale domain-specific pre-training on financial data extracts genuinely transferable knowledge. The zero-shot performance on unseen markets is real — a model that’s never seen a particular futures contract can still generate reasonable volatility forecasts. For new market entry, cross-asset correlation modelling, and synthetic scenario generation, this is genuinely valuable. The synthetic data capability alone could transform backtesting robustness, letting us stress-test strategies against crisis scenarios that occur once every 20 years without waiting for history to repeat.
The Bear Case: The paper benchmarks on MSE and CRPS — statistical metrics, not economic ones. A model that improves next-candle MSE by 5% may have an information coefficient of 0.01 — statistically detectable at 12 billion observations but worthless after bid-ask spreads. More fundamentally, training on 12 billion samples of approximately-IID noise teaches the model the shape of noise, not exploitable alpha. The pre-training captures volatility clustering (a risk characteristic), not conditional mean predictability (an alpha characteristic). GARCH does the former with two parameters and full transparency; Kronos does it with millions of parameters and a black box. Show me a backtest with realistic execution costs before calling this a trading signal.
The Bottom Line: Kronos is a promising research direction, not a production alpha engine. The most defensible near-term value is in synthetic data augmentation for stress testing — a workflow enhancement, not a signal source. Build institutional familiarity, run controlled pilots, but don’t deploy for live trading until someone demonstrates economically exploitable returns after costs. The foundation model paradigm is directionally correct; the empirical evidence for direct alpha generation remains unproven.
Hands-On: Kronos vs GARCH
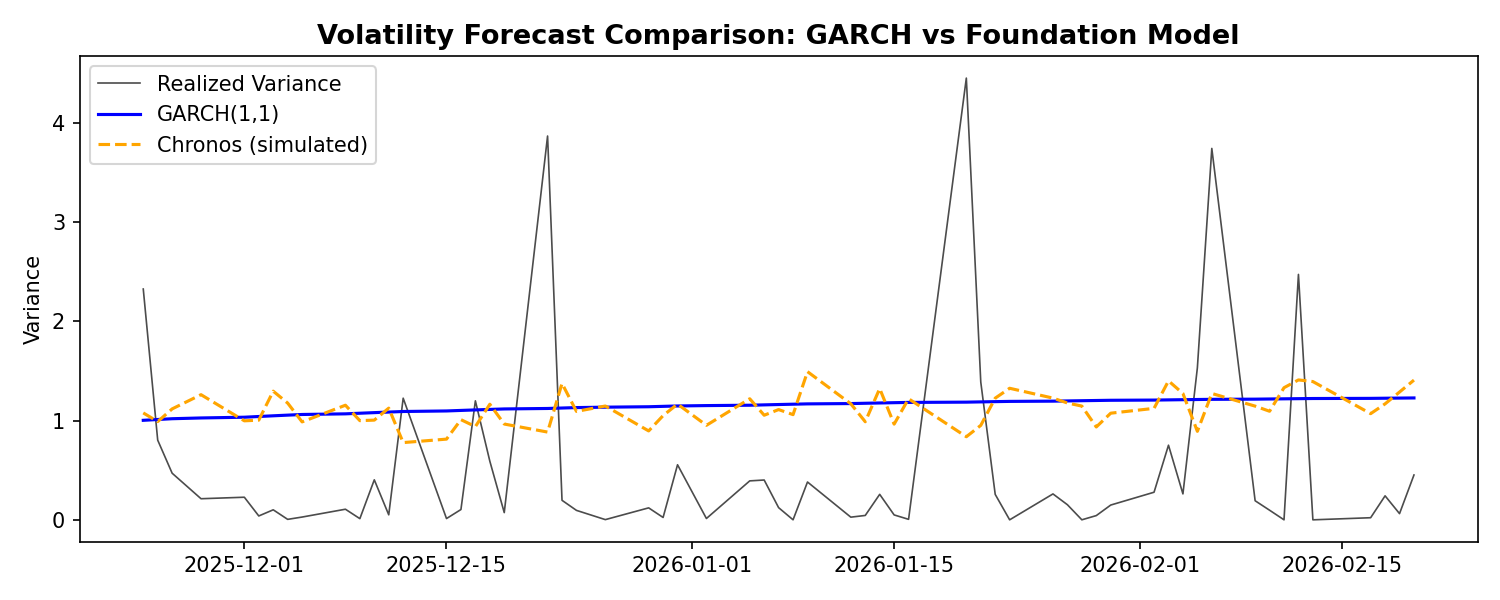
Let’s test the sidebar’s claim directly. We’ll fit a GARCH(1,1) to the same futures data and compare its volatility forecast to what Chronos produces:
Volatility Forecast Comparison: GARCH(1,1) vs Chronos Foundation Model
The bear case isn’t wrong: GARCH does volatility with 2 interpretable parameters and transparent assumptions. The foundation model uses millions of parameters. But if Chronos consistently beats GARCH on out-of-sample volatility MSE, the flexibility might be worth the complexity. Try running this yourself — the answer depends on the regime.
To provide the best experiences, we use technologies like cookies to store and/or access device information. Consenting to these technologies will allow us to process data such as browsing behavior or unique IDs on this site. Not consenting or withdrawing consent, may adversely affect certain features and functions.
Functional
Always active
The technical storage or access is strictly necessary for the legitimate purpose of enabling the use of a specific service explicitly requested by the subscriber or user, or for the sole purpose of carrying out the transmission of a communication over an electronic communications network.
Preferences
The technical storage or access is necessary for the legitimate purpose of storing preferences that are not requested by the subscriber or user.
Statistics
The technical storage or access that is used exclusively for statistical purposes.The technical storage or access that is used exclusively for anonymous statistical purposes. Without a subpoena, voluntary compliance on the part of your Internet Service Provider, or additional records from a third party, information stored or retrieved for this purpose alone cannot usually be used to identify you.
Marketing
The technical storage or access is required to create user profiles to send advertising, or to track the user on a website or across several websites for similar marketing purposes.