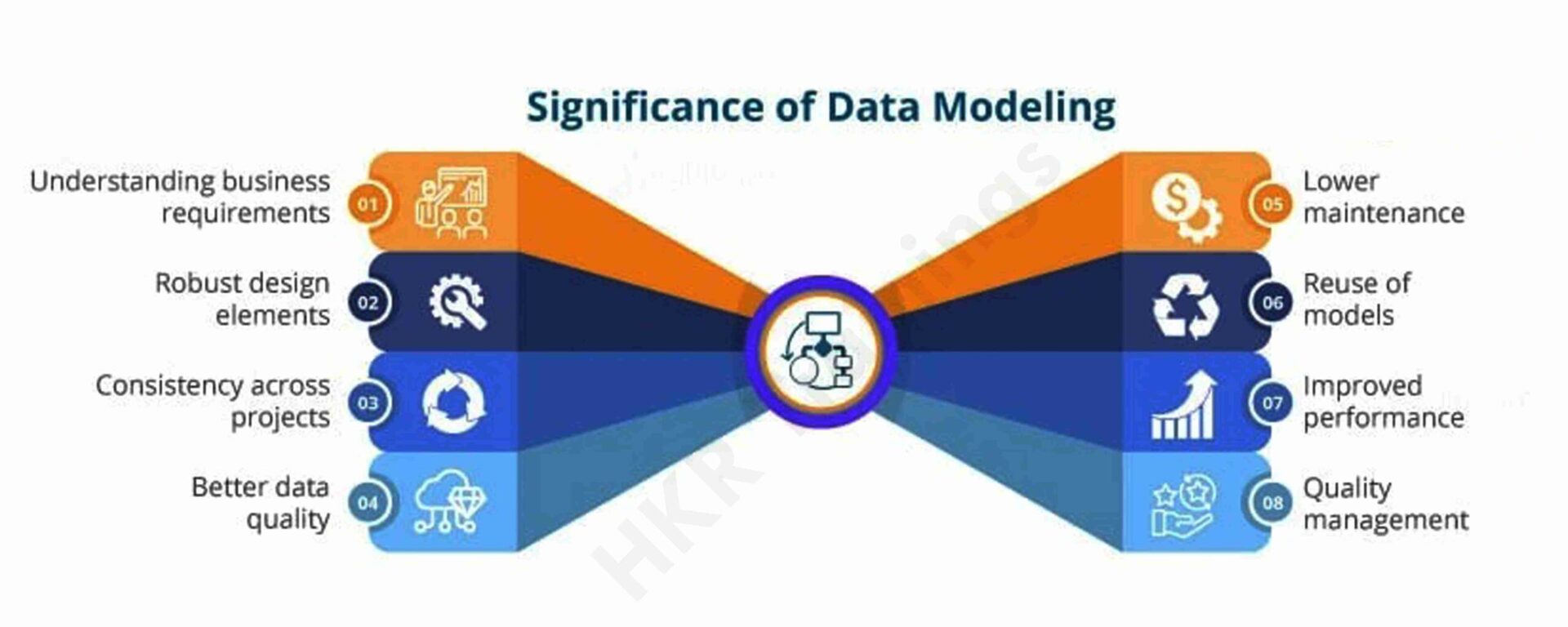
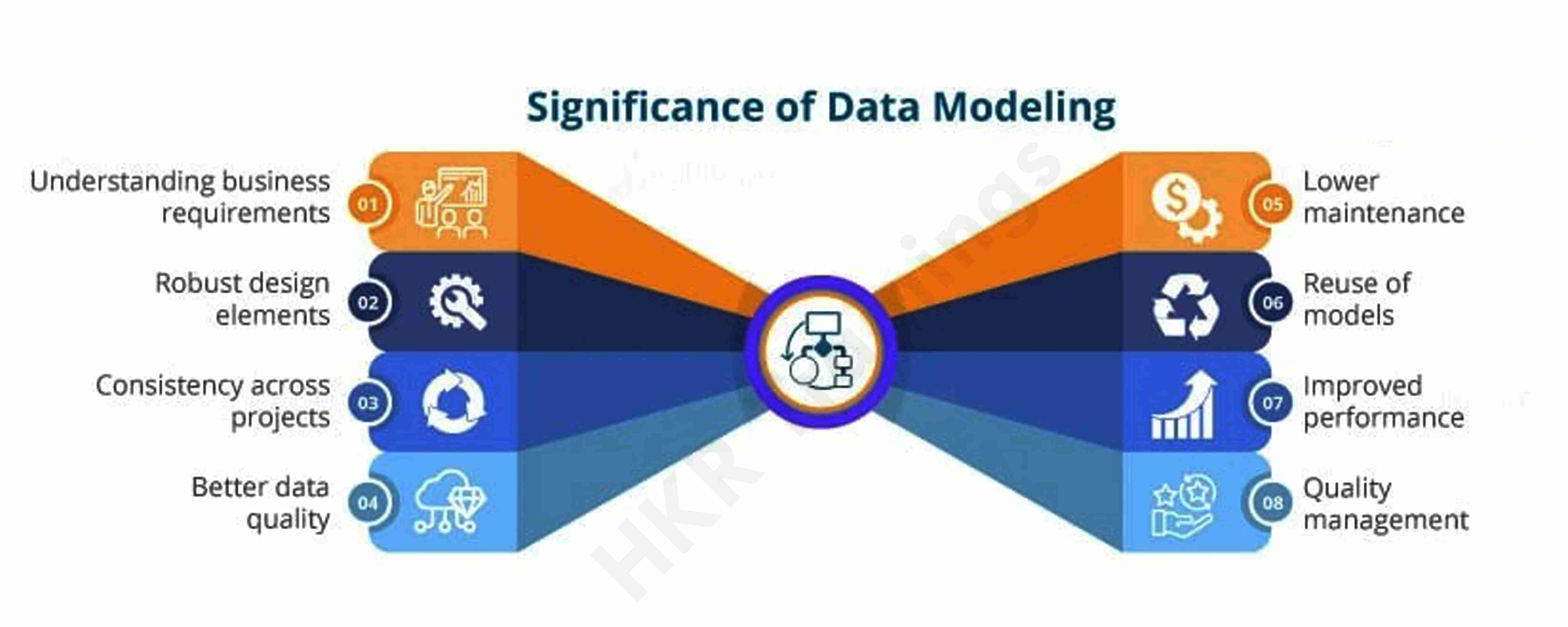
A brief introduction to IBM SIEM Qradar:
SIEM Qradar is a powerful security intelligence tool and offers cross-environment support. SIEM Qradar is a child product of the company “IBM”. The main aim to develop this tool is to provide accurate detection and prioritize the threats across multiple enterprises. This SIEM Qradar also offers data intelligent insight that helps the team to notify and respond quickly to any threat incident that happens. IBM SIEM Qradar can also be implanted in a cloud environment and on premise infrastructure to protect the data and devices. The core functionalities of IBM SIEM Qradar included are data collection and flow collections. Flow data consists of information about network activity information and hosts information between any two networking servers.
Want to get Qradar Training From Experts? Enroll Now to get free demo on Qradar Online Course!
Overview of IBM SIEM Qradar:
As we discussed above, IBM SIEM Qradar is a security and data protection platform, mainly developed to secure the business data, reduces risk, and protect the device from any kind of threats. There are various IBM SIEM Qradar console components are available such as Qradar product interface, flow views, administrative functions, asset information, reports, real time events, and offenses. Sometimes this Qradar acts as a host between any two networking sessions to protect the business data. One more important function of SIEM Qradar is to collect the IDS AND IPS cisco events with the help of SDEE protocol or commonly known as “Security device event exchange”.
The architecture of Qradar:
The Qradar architecture defines the core functionality and work nature of the system. In this section, we are going to determine the overall functionality of Qradar:
The following diagram explains the Qradar Architecture:
IMAGE

SIEM Training
- Master Your Craft
- Lifetime LMS & Faculty Access
- 24/7 online expert support
- Real-world & Project Based Learning
The core functionalities of IBM SIEM Qradar included are data collection, process, integrate, aggregate, and store them in an appropriate data base management system. Qradar platform makes use of these data to manage network security by offering real-time information, monitoring, and responds to various network threats. IBM SIEM Qradar architecture is based on a modular architecture that supports real-time data visibility of any information technology information, and also helps for threat detections. There are various Qradar modules included are Qradar platform, Qradar vulnerability, Qradar data manager, Qradar risk manager, and Qradar incident forensics. The Qradar security intelligence platform composed of three layers they are data collection, data searches, and data processing.
[ Related Article: qradar training ]
Subscribe to our YouTube channel to get new updates..!
Qradar core components:
The following are the IBM SIEM Qradar core components, they are;
1. Qradar Console:
a. Qradar console offers the user interface, real time data events, administrative functions, offenses, and asset information.
b. In the distributed Qradar data deployment, we make use of the Qradar console to manage the networking hosts and components functionalities.
2. Qradar event collector:
a. The Qradar event collector helps to collect the events from remote and local log sources and then normalizes the raw data log source events.
b. Usually these event collectors are types of bundles and coalesces identical events to transfer the data to the data processor.
c. The event collector does not store the events locally and parse the events for storage.
d. This event collector will be assigned to an EPS license that matches the Qradar event processor.
3. Qradar Event processor:
a. This Qradar event processor helps to process the events that are collected from one or more event collectors.
b. The event processor processes the Qradar events with the help of the Customs Rules engine (CRE). These events are predefined and execute the action that is specified for the rules.
c. Each event processor consists of local storage and the data will be stored on the Qradar processor.
d. You can also add an event processor component to an all-in-one appliance and each event processing function will be moved from the all-in-one appliance to the Qradar event processor.
4. Qradar Qflow collector:
a. The Qradar flow collector helps to collect the data flows by connecting them to the SPAN port or any networking TAP portal.
b. These types of Qradar Qflow collectors are not designed for full packet capture systems. To get the full packet capture you need to review the incident forensic options.
c. User can also install a Qradar Qflow collector on their own hardware system and also enables you to make use of Qflow collector appliances.
5. Qradar flow processor:
a. The Qradar flow processor helps to flow data from one or more Qflow collector appliances. The flow processor appliance can also be used to collect the external networking data flows they are Net Flow, S flow, and J flow.
b. User can also use the Qradar flow processor appliance to scale the Qradar deployment to maintain the higher data flow per minute.
c. This type of flow processor consists of on board data flow processor and internal storage.
6. Qradar data nodes:
a. This Qradar data node supports new and existing Qradar deployment to ass appropriate storage and processes them as per your requirement.
b. Qradar data node also helps to increase the data search speed and offers more hardware resources to run your device.
7. Qradar App host:
a. This Qradar App host is used to manage the network host to run your applications. App host offers extra data storage, CPU resources, and Memory for your application without affecting the processing capacity of the Qradar console.
b. The applications such as User behavior analytics and machine learning analytics need more resources on the Qradar console.
Qradar appliances:
The following are the various Qradar appliances:
1. Qradar security intelligence platform appliances:
IBM Qradar security intelligence platform is very comprehensive, offers next-generation security solutions and risk management appliances. This appliance offers services like integrated log management, event management, and security services.
2. Qradar security management appliances:
This is a Qradar network security management appliance and related software application. This offers enterprise-level integration with an integrated framework that helps to combine disparate networks.
3. Qradar QFLOW collector appliances for security intelligence:
This IBM Qradar Qflow collector mainly used for security intelligence management appliances and this offers advanced network data analytic solutions.
Features of IBM SIEM Qradar:
Below are the advanced features of IBM SIEM Qradar:
1. Task scanner – the task scanner component scans the specified properties, on a scheduled time intervals. This scanning mechanism executes the tasks when the property value matches a specified value.
2. Script Engine – this scripting engine is a pluggable component module that provides the triggering and plugin points for the Identity management system. It can be performed using JavaScript and Groovy programming language.
3. Policy Service – This component used to apply the validation procedures to objects or properties, when they are updated or created.
4. Audit Logging – Audit logging performs the logging activities of all the relevant system users and also configures the log stores. This uses the reconciliation data as a base for reporting and activity logs to capture the internal and external object’s operations.
5. Repository – This component abstracts the pluggable persistence layer. IDM framework modular provides Reconciliation of data and synchronization with several external data stores like relational databases (RDBMS), LDAP data servers, CSV, and XML files.
The Repository API component uses the JSON-based object model with RESTful automation tool principles. The main purpose of using this component is for testing and embedded instances for Qradar services.
Benefits of IBM SIEM Qradar:
Below are the key benefits of IBM SIEM Qradar:
1. Easy to deploy, scalable model using stackable distributed appliances.
2. Qradar doesn’t require any storage database management system.
3. Offers automatic failover and disaster recovery.
4. Cloud environment, on premise, and hybrid deployment.
5. Software, hardware, and virtual resource deployments.
Join our Juniper Networks Certified Internet Professional Training today and enhance your skills to new heights!
SIEM Training
Weekday / Weekend Batches
Conclusion:
In this IBM SIEM Qradar blog, we have tried to cover basic to core concepts of Qradar and to write them in an understanding purpose we have taken expert guidance. SIEM Qradar is an IBM product and mainly used to protect the business data, devices, and software components from any malware attacks and threats. One more important point to be considered here, this Qradar tool can also be deployed on cloud and on premise environment. If you are working as a security architect, then this blog will be more beneficial.

Stephan is the sports journalist for the Maple Grove Report.