Months after it was first rumored that Sebastian Stan would join the cast of The Batman: Part II, the actor is finally commenting on the project.
After years of playing Bucky Barnes in the Marvel Cinematic Universe, Sebastian will be joining the DC Comics Universe.
Sebastian told Deadline that the movie will be “a challenge, like everything else. I feel like it’s a really ambitious movie and I think if we do it all right — and obviously I’m so excited about Matt Reeves [directing] because he’s been one of my favorites for a long, long time — I really think it’s going to blow people away. It’s going to surprise a lot of people, I think, too.”
It is rumored that Sebastian will play Harvey Dent opposite Robert Pattinson as Batman.
Sebastian‘s trainer Jason Walsh took to Instagram to share a video from the beginning of the actor’s training process.
“Can’t explain just how excited we are to be training Sebastian for Batman. This is going to be epic! Sebastian is one of the kindest clients we’ve ever had the opportunity to work with. In this clip I introduced him to @rise.311 protein to start recovering from training,” Jason wrote.
On joining the film, Sebastian added, “Obviously there’s a reason why Batman’s been re-occurring for so many years, and why so many kids love Spider-Man. When you’re thinking of, honestly, just anything positive for young men. If you’re a teenager and you’re growing up and you’re watching that, it’s about a kid being odd and figuring his way into things. And it works in very subtle ways.”
AI systems today are used to perform almost all types of tasks; they can search, recommend, and share answers for a massive amount of data. However, one major concern is that machines do not fully understand the context.
This is where the need for embedding models that allow semantic search, share powerful AI responses, recommendation engines, or retrieve information at scale, and more comes in. These models are widely used for transforming text, images, and other data types into vectors that capture semantic meaning.
Thus, the best embedding models are widely adopted by organizations today to perform powerful tasks. With so many options available in the market, it’s a challenging task to pick the right embedding model for building high-performance AI systems. To make your job easy, we’ve covered the top 5 open-source embedding models in this blog post that you can start using in 2026.
Understanding Embedding Models
Embedding models play a key role in converting text, images, code, and other data into vectors that capture their semantic meaning rather than keywords. With this, machines can accurately understand context, similarity, and user intent.
The following are some of the use cases of embedding models:
Powering search
Recommendation engines
Retrieval-Augmented Generation (RAG) systems
Why Choose Open-Source Embedding Models?
Embedding models stand as a cornerstone in building a memory system or rag system that determines how accurate information is stored, retrieved, and understood. If you’re looking for maximum optimization, flexibility, and control, open-source models are an ideal option.
They are domain-specific, can run anywhere, and are useful for preventing vendor lock-in. Alongside, open-source embedding models can meet stringent data, latency, and budget constraints.
Another big win is that these models provide greater transparency and better debugging capabilities and come with better explanatory capabilities.
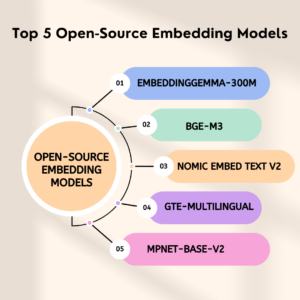
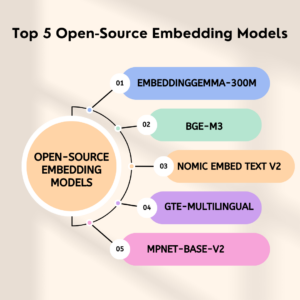
List of Top 5 Open-Source Embedding Models
1] EmbeddingGemma-300M
Embedding Gemma 300M is a lightweight multilingual embedding model created by Google DeepMind to allow efficient and high-quality text representation. The model is based on Gemma3 but uses only 300 million parameters; it still delivers good results in multilingual retrieval and semantic similarity tasks. A very small size is ideal when implementing AI apps in on-device solutions and edge environments.
Key Features:
Lightweight model optimized for real-time applications
100+ languages for multi-lingual and cross-lingual tasks
Faster embedding generation
Low memory usage (200 MB or below)
Best for: Multilingual text retrieval and embedding tasks on edge devices with fewer resources.
2] bge-m3
Another top-ranking open-source embedding model, bge m3 from BAAI, is mainly used in hybrid lexical-semantic search systems that need flexibility. The multi-representation encoder is designed to facilitate dense, sparse, and hybrid vector retrieval.
It is very flexible with complex search conditions and long document processing. It provides a comprehensive understanding of context by combining different retrieval methods in a single pipeline, thereby enhancing search coverage and relevance.
Key Features:
Optimized for long-document processing
Flexible integration across advanced AI systems
Helps in improving contextual search by combining different retrieval techniques
Best for: Multilingual semantic search, production-ready RAG systems, and more.
3] Nomic Embed Text V2
Nomic Embed Text V2 is a popular multilingual embedding model from Nomic AI; it’s built for scale. This model can ideally handle longer inputs than many smaller models. It relies on a Mixture-of-Experts (MoE) architecture to produce high-quality, efficient text embeddings. The feature of large multilingual datasets is trained to offer high efficiency and scalability of semantic search, RAG, and recommendation use cases.
Key Features:
Right execution in BEIR and MIRACL.
Supports programmable embedding size (768 to 256)
Entirely open-source, and training data and model weights provided
Best for: Multilingual semantic search and scalable RAG systems requiring efficiency and flexibility.
4] GTE-Multilingual
gte-multilingual-base is a dense retrieval model that supports more than 70 languages; it is used in cross-lingual search and global content discovery. This open-source embedding model offers high-quality multilingual retrieval accuracy, but its broad language coverage may lead to slightly higher latency than highly tuned single-language models.
Key Features:
Cross-linguistic retrieval of 70+ languages
Good search and knowledge discovery accuracy on a larger scale
Can process different types of content in international systems
Best for: Multilingual knowledge bases, international search systems, and international customer support systems.
5] MPNet-Base-V2
MPNet-Base-V2 is mainly a transformer-based embedding model, which is highly optimized for semantic similarity, clustering, and content understanding tasks. It can capture contextual meaning but can be slower to infer and less precise in exact-match retrieval than a more specific retrieval model.
Key Features:
Good semantic similarity and clustering
Good at analytics, suggestions, and deduplication
Rich contextual insight into textual content
Best for: Semantic analytics, recommendation engines, and content similarity detectors.
Final Words on Top Open-Source Embedding Models
Here, we have understood the top embedding models and how they power AI systems in different ways. Knowing each of these in detail can help you choose the best one for your requirements in 2026. No matter if you’re building a memory agent or a research assistant, it all depends on the model for how fast, scalable, and efficient it is.
1. Why use open-source embedding models? Answer: They offer customization, flexibility, and lower cost without vendor lock-in.
2. Are open-source embedding models reliable? Answer: Yes, most of them provide a high degree of accuracy and functionality in search, RAG, and AI apps.
To provide the best experiences, we use technologies like cookies to store and/or access device information. Consenting to these technologies will allow us to process data such as browsing behavior or unique IDs on this site. Not consenting or withdrawing consent, may adversely affect certain features and functions.
Functional
Always active
The technical storage or access is strictly necessary for the legitimate purpose of enabling the use of a specific service explicitly requested by the subscriber or user, or for the sole purpose of carrying out the transmission of a communication over an electronic communications network.
Preferences
The technical storage or access is necessary for the legitimate purpose of storing preferences that are not requested by the subscriber or user.
Statistics
The technical storage or access that is used exclusively for statistical purposes.The technical storage or access that is used exclusively for anonymous statistical purposes. Without a subpoena, voluntary compliance on the part of your Internet Service Provider, or additional records from a third party, information stored or retrieved for this purpose alone cannot usually be used to identify you.
Marketing
The technical storage or access is required to create user profiles to send advertising, or to track the user on a website or across several websites for similar marketing purposes.